
こんにちは、パレイド思想部の橘です。
少し前に、連載「pareido.jp を AI リニューアル」の第 6 回で、媒体に動画を取り込む話を書きました。
 パレイドpareido.jp を AI リニューアル(6)|YouTube と並走させるこんにちは、パレイド思想部の橘です。 前回は、AI編集者の前提としたサイト設計と、多様性の拡張という話を書きました。 媒体の中身——書き手側の構…
パレイドpareido.jp を AI リニューアル(6)|YouTube と並走させるこんにちは、パレイド思想部の橘です。 前回は、AI編集者の前提としたサイト設計と、多様性の拡張という話を書きました。 媒体の中身——書き手側の構…
本連載「AI Video Pipeline」は全 3 回で、AI動画制作の可能性を記録するものです。第 1 回の今回は、音声 (朗詠) を作るまでを扱います。第 2 回 (5/10 公開予定) は画像と動画のガチャ、第 3 回 (5/11 公開予定) はアバターの合成 を扱います。
本記事のポイントは、Photoshop や DAW などの編集ソフトと向き合う過程が、AI との対話というインタラクションに置き換わる——そして、結果として見えてきた新しい可能性。第 1 回では、音声素材の作成を取り扱います。
本記事は LLM による自動執筆パイプラインで生成されました。現在は人間が補助していますが、pareido.jp では最終的に AI が自律的にコンテンツを制作できる仕組みの構築を目指しています。
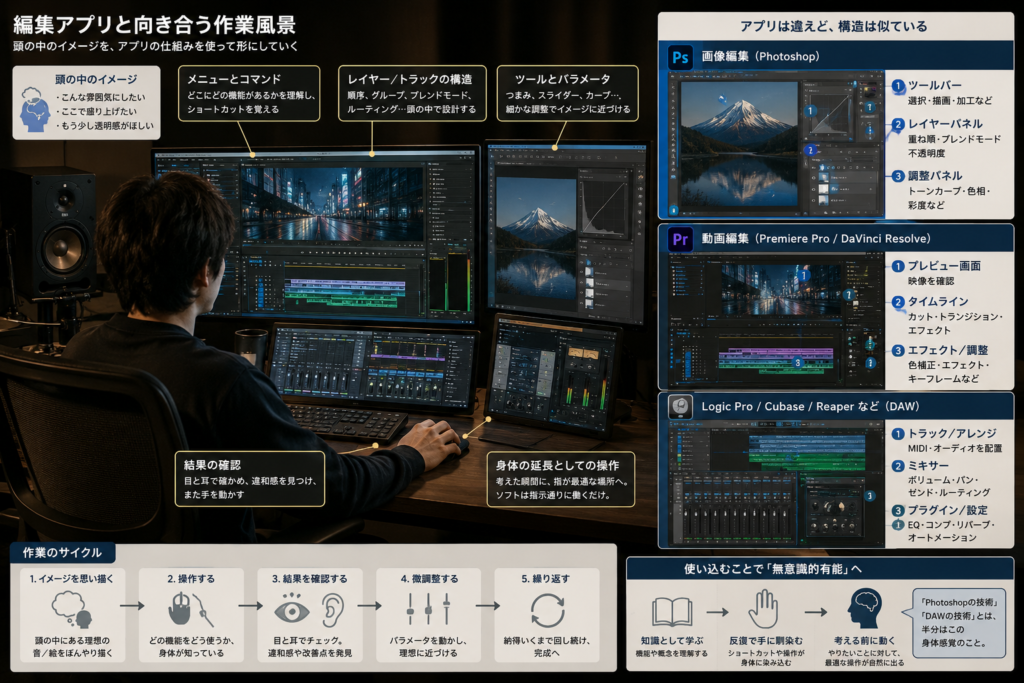
編集アプリと向き合う作業風景
少しだけ昔の話を挟みます。動画や画像や音の素材を、人間が手で作る——というのは、ほんの数年前まで当たり前の話でした。
素材は自分で撮影したりインターネットで入手したり様々ですが、編集にはアプリが必要で、Premier や Photoshop で開き、画面上には GUI のレイヤーパネルやツールバーが所狭しと並ぶ。頭の中にあるイメージを実現するには、どのように画像を加工する機能がどこにあるかを理解し、メニューのどこにそのコマンドがあるかを覚え、ショートカットを指に染み込ませ、レイヤーの順序とブレンドモードを頭の中で組み立てます。動画や画像に限らず、DAW (Logic Pro や Cubase や Reaper) も同じです。トラックを縦に積み、プラグインを挿し、オートメーションを書き、ミックスダウンする。Premiere や DaVinci Resolve でタイムラインを切り貼りするときも、構造は似ています。
これらのソフトを使いこなすというのは、ソフトが用意したパネルとコマンドの体系を、自分の身体の延長として馴染ませることでした。画像で「ここの色をもう少し落としたい」と思ったら、トーンカーブを開いて、暗部のポイントをドラッグする。指がそう動く。音声で「このボーカルにかすかな空気感を足したい」と思ったら、リバーブをインサートして、プリディレイを 20ms くらいに置き、ウェットを 8% に絞る。指がそう動く。
ここで作業している個人は、自分の手が延長されたように感じながら作業をしているでしょう。画面と向き合い、ツールバーに手を伸ばし、出てきた結果を耳と目で確かめ、また手を動かす。ソフトはこちらが押したボタンの通りにスムーズに指示通りに働くだけです。
クリエーター向けのアプリを数ヶ月から数年使い込むと、こうした作業はかなりの程度、「無意識的有能」な状態となり手に馴染みます。やりたい音/絵がぼんやり頭の中にあって、どのパネルのどのつまみをどう動かせばそこに近づくか、「できること」を身体が知っている。「Photoshop の技術」「DAW の技術」というのは、半分はその身体感覚のことです。
AI 対話への移行——「素材を作る」の別解
今回、動画を作るときに、わたしが向き合っていたのはパネルでもツールバーでもありませんでした。AI との対話の窓です。
具体的には、VS Code と Claude 拡張の組み合わせを利用しています。もちろん、他の AI や開発環境の組み合わせでも問題ありません。これに、Python, ffmpeg, ComfyUI 等を組みわせれば、音声や画像・動画クリップ生成を、すべて対話ベースで行うことができます。また、AI の「壁打ち」を活かして、新しい方向性にも柔軟に対応できます。
例えば ACE-Step (歌声生成モデル) を回す前段で、編集者の Claude と「どういう声を狙うか」を言葉で詰めていく作業がありました。狙いを言葉にし、AI 側の応答を読み、それを踏まえて次の言葉を返す。生成ジョブを 1 本投げ、出てきた音を聴き、何がずれているかをまた言葉にする。
これは、アプリで画像や音声を加工するのとは本質的に性質が違います。AI との対話では、例えば「もう少し古い感じで」と伝えたとき、AI 側が「古い」をどう解釈するか、画像や音としてどう出てくるか、出してみるまで分からない。指の延長として動く道具ではなく、こちらの言語化できない部分を含め、意図を読み解こうとする「相手」と話している感触です。
ここで起きている変化は二つあります。
一つ目は、作業を言語化しながら進めるということ。指の身体感覚で済んでいた手順が、いちど言葉に翻訳されます。「暗部のトーンカーブを 10 持ち上げる」ではなく、「もう少しだけ、闇に沈んでいるところに目が入りやすい絵にしたい」と書く。作業の手間は、それ自体としては明らかに増えていますが、熟練の技術というハードルは大きく下がっています。
二つ目は、こちらの指示が曖昧でも、相手が解釈を試みること。アプリは柔軟に設計されていますが、それでも事前に実装された機能以外の能力は持ちません。AI 対話は、曖昧な入力でも何かしらの出力を返してきます。返ってきた出力を見て、「いや、わたしが狙っていたのはこっちじゃない」と気づき、言葉を足す。逆に、思っていたものとは別のアイディアが出てくることもある。成果物の精度が、対話を通じた言語化とともに上がっていくという構造です。
完全に編集ソフトの操作に置き換わったわけではありません。出てきた音や絵を最後に整える段階では、いまでも DAW や動画編集ソフトを開きます。頭の中に「正解」があるケースは、アプリの方が早い。けれど、素材を「作る」工程の主軸は、ソフトのパネル操作から AI との言葉の往復に移りつつある——これが今回の制作で実感した手触りです。

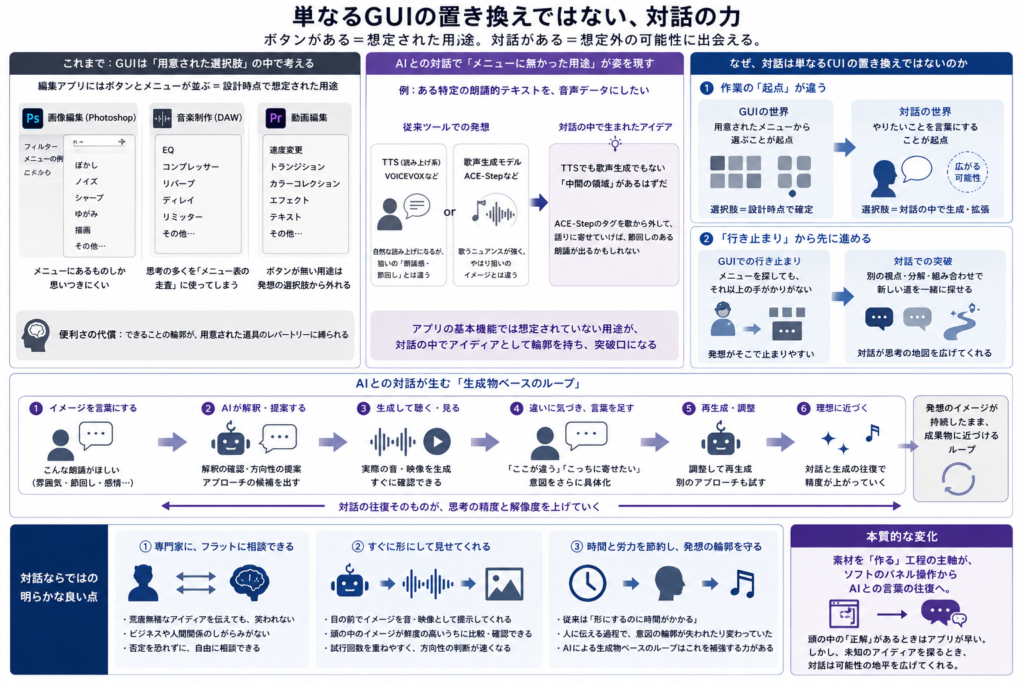
単なるGUIの置き換えではない、対話の力
編集アプリには、ボタンとメニューが並びます。Photoshop なら、「フィルター」メニューを開けば、ぼかし、ノイズ、シャープなどが並ぶ。DAW なら EQ、コンプ、リバーブ。動画編集ソフトなら速度変更、トランジション、カラーコレクション。「ボタンがある」というのは、その用途がソフトの設計時点で想定されていた、ということです。
逆に言うと、ボタンが無い用途は、ソフトと向き合っている限り発想しにくい。「Photoshop で何ができるか」を考えるとき、無意識のうちに頭の中の「メニュー表」を走査しています。メニューに無いものは、思いつきの選択肢からそもそも外れる。これは便利さの代償で、用意された道具のレパートリーが、できることの輪郭を狭めてしまう。
AI との対話の中で、まさに「メニューに無かった用途」が対話で姿を現すケースがありました。ある特定の朗誦的テキストを音声データにしたい、という発想でした。一般的なツールで考えると、VOICEVOX のような TTS (読み上げ系) で読ませるか、ACE-Step のような 歌声生成モデルで歌わせるか。どちらにも明確な用途がある。けれど、どちらも、狙っていたイメージとは違う。
「TTS でも歌声生成でもない、その中間の領域があるはずだ」「ACE-Step のタグを歌から外して、語りに寄せていけば、節回しのある朗誦が出るかもしれない」——という、アプリの基本的な機能では想定していない用途も。AI とのやり取りのなかで、アイディアとして輪郭が浮かび上がってくる。対話のなかで起きたのは、その行き止まりから先の話でした。
いくつか明らかに良い点があります。まず AI は専門家ですが、フラットに気兼ねなく相談ができます。荒唐無稽なアイディアを伝えて笑われることもなければ、ビジネスや人間関係のしがらみで、否定的な意見を飲み込んで迎合することもありません。また、AI は目の前でそれを形にして見せる能力が高く、発想のイメージが頭の中にあるうちに、実際の成果物と比較ができる。従来であれば、それを形にする過程で時間がかかり、あるいは人に伝える中で、アイディアの当初の輪郭は失われたり、変わってしまう。AI による生成物ベースでのループは、むしろこれを補強する力があります。
次回に向けて
個人クリエイターが、AI を通じて、従来複数人でなければ難しかった作業を実現していく——これは思想部で繰り返し書いてきた構図です。
経済合理性の側から見ても、1 ジョブが数十秒〜数分のガチャで、5 世代回しても合計で数十分の計算時間しかかかりません。これを仮に組織規模の人日単価に換算すると、時間も費用も桁がいくつか違ってきます。けれども、これは目的ではなく結果のほうです。経済効率を目指して採用するのではなく、対話で輪郭を引き直しながら回せることに意義がある。ここに AI と対話型で素材作りを進めることの本質的な価値です。
朗詠の音声ができてから、次は 画像と動画の量産 に話が進みます。SDXL で 1 枚絵を起こし、Wan2.2 i2v で動画化する。同じ題材を月岡芳年版 (浮世絵調) と明治古写真版 (セピア調) の 2 系統で並行生成して、どちらが「平地人を戦慄せしめよ」の格に合うかを見る——という、もう一段別のガチャの話です。第 2 回では、編集ソフトと向き合っていた時代の作業感を、今度は画像側でもう一度なぞり直すことになります。同じ転換が、音声側と画像側でどう違う形で現れるか、というのが見どころです (5/10 公開予定)。