

今回は、前回記事でVibe codingで作成したRSSフィード読み込みに、本文を取得してMarkdownに追加する機能を追加してみます。
 パレイドVibe codingを実践してわかった注意点:失敗しにくい使い方Vibe codingは便利ですが、そのまま信じると危険です。実際のコード生成例を題材に、注意点と実践で使える活用方法を整理します。
パレイドVibe codingを実践してわかった注意点:失敗しにくい使い方Vibe codingは便利ですが、そのまま信じると危険です。実際のコード生成例を題材に、注意点と実践で使える活用方法を整理します。
ChatGPTへのプロンプト例
前回の記事で作成したコードは、feedparserで取得したRSSフィードをMarkdown形式で出力するものでした。
RSSフィードは一覧取得に便利ですが、記事の本文は含みません。 今回はRSS中のリンクから本文まで取得し、Markdown形式に加えて保存するコードを作成します。
ChatGPTに下記のような維持を与えてコードを出力してもらいます。
添付のコードに本文記事まで取得してMD構造に組み込んで出力する改良を加えて。パッチ適用による編集
今回は、ChatGPTアプリとVS Codeを連携させて「パッチ編集」の形でコードを追加してもらいました。
また、RSSサイトの例としてテクノエッジ TechnoEdgeのURLを事前に埋め込んで与えてあります。(AIニュースも扱っており参考になり、かつ記事の構造もシンプルなため例とさせていただきました)
緑色簿部分が、パッチで「追加」された部分。今回はありませんが赤色は「削除」を示します。
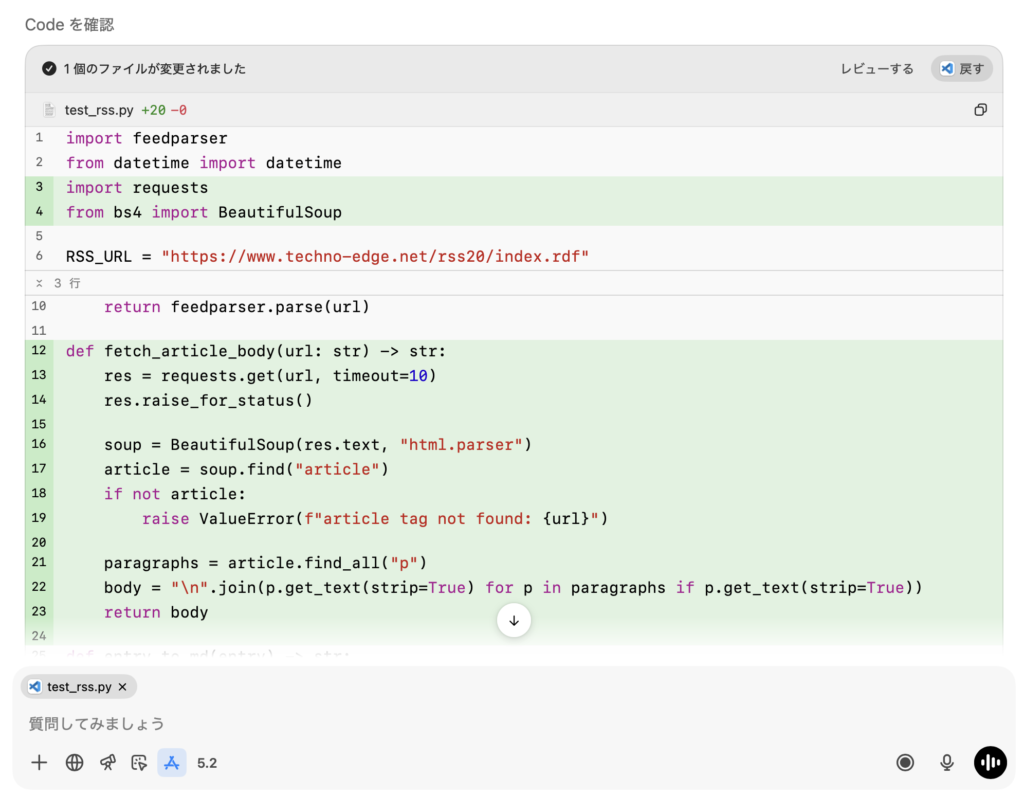
これぐらいの規模のコードであれば、比較的スムーズに追加できます。
import feedparser
from datetime import datetime
import requests
from bs4 import BeautifulSoup
RSS_URL = "https://www.techno-edge.net/rss20/index.rdf"
OUTPUT_MD = "techno_edge.md"
def fetch_rss(url: str):
return feedparser.parse(url)
def fetch_article_body(url: str) -> str:
res = requests.get(url, timeout=10)
res.raise_for_status()
soup = BeautifulSoup(res.text, "html.parser")
article = soup.find("article")
if not article:
raise ValueError(f"article tag not found: {url}")
paragraphs = article.find_all("p")
body = "\n".join(p.get_text(strip=True) for p in paragraphs if p.get_text(strip=True))
return body
def entry_to_md(entry) -> str:
title = entry.get("title", "No Title")
link = entry.get("link", "")
summary = entry.get("summary", "").strip()
published = entry.get("published_parsed")
if published:
published = datetime(*published[:6]).strftime("%Y-%m-%d %H:%M")
else:
published = "unknown"
md = []
md.append(f"## {title}")
md.append(f"- URL: {link}")
md.append(f"- Published: {published}")
md.append("")
body = fetch_article_body(link)
md.append(summary)
md.append("")
md.append(body)
md.append("")
return "\n".join(md)
def rss_to_markdown():
feed = fetch_rss(RSS_URL)
md_lines = []
md_lines.append(f"# TechnoEdge RSS")
md_lines.append("")
md_lines.append(f"- Source: {RSS_URL}")
md_lines.append(f"- Generated: {datetime.now().strftime('%Y-%m-%d %H:%M')}")
md_lines.append("")
for entry in feed.entries:
md_lines.append(entry_to_md(entry))
with open(OUTPUT_MD, "w", encoding="utf-8") as f:
f.write("\n".join(md_lines))
print(f"saved: {OUTPUT_MD}")
if __name__ == "__main__":
rss_to_markdown()これ以上コードの規模が大きなったり複雑になると、生成AIが全体を把握しきれず、不整合が発生しやすくなります。 必要なコードを消してしまうことも多いため、よく見て適用するか、必要に応じて「戻す」処理を行います。
今回も、ごく短い指示で、実際に動くコードを1分程度で生成してきました。
注意点
今回も、生成AIが出力したコードは、短いですが注意点も多くあります。
必要ライブラリと技術的注意点
このコードを動かすには、beautifulsoup4, requestsなどのライブラリが必要です。
下記のようにインストールしておきます。詳細や手順は生成AIに相談しても良いでしょう。
pip install beautifulsoup4 requestsAIはbeautifulsoup4とrequestsを使用したコードを出力しましたが、ウェブサイトの構造によってはうまく動作しません。 例えば、JavaScriptで動的にコンテンツを生成しているサイトでは、requestsだけでは本文が取得できないことがあります。
また、このコードは特定のサイト構造に依存しているため、すべてのRSSフィードで正しく動作するわけではありません。 実際のRSSフィードを与えると、AIの知識に基づいて修正してくれる場合もありますので、必要に応じて試してみてください。
PlaywrightやSeleniumなどのヘッドレスブラウザを使う方法がより汎用性が高くなりますが、今回はシンプルさを優先しています。
スクレイピングの注意点
今回実装したような処理はWebスクレイピングと呼ばれます。
スクレイピングは、ニュースサイトなどのコンテンツを自動的に取得する手法として広く使われています。 記事を提供している側もある程度許容していると考えられますが、サーバーへの負荷やコンテンツの権利関係への懸念から、禁止しているサイトもあります。
生成AIはこうした規約や法律に関する知識やユーザーへの注意喚起が不十分な場合があるため、利用規約を確認の上で実行することが重要です。また、規約上の問題がなくとも、サーバーに過度な負荷をかけないよう、適切な間隔をあけてアクセスすることも重要です。
また、ウェブサイト側の変更でタグ構造が変化しやすいため、定期的に動作確認とメンテナンスを行うことをお勧めします。
生成AIに提案の妥当性を確認させる
Vibe codingでは、スクレイピングのように、「便利だけれど利用には注意が必要」なテクニックをAIが紹介してくる場合があります。 AIは特に説明や注意喚起などは行いませんし、質問をしても知識や理解が不十分な説明もあります。
理想は自分自身で提案を調べて確認することですが、手間と時間がかかるため、このスタイルではVibe codingの良いところを活かせません。
これらの点を踏まえる、生成AI自身に自分の提案を客観的に見て、最新情報に基づいた内容であるかを確認させる方法が有効です。
下記の点について、最新の情報をWebで調べて客観的に教えてください。
・このような処理を行う上で注意すべき点があるか。
・セキュリティ上の懸念はあるか。
・利用規約・法的な観点で問題はないか。
・権利関係はクリアか。前回と同様、カットオフやハルシネーションを回避するため、Webで最新情報を調べること明示的指示するのがコツです。
まとめ
今回も、ごく短い指示でVibe codingは動くコードを生成してきました。
既に保守性では疑わしい点が出てきていますが、とにかく手早く動くコードが得られることがメリットのため、もう少しこのまま実装を進めてみます。
次回はLLMを使って本文の要約を行い、Markdown形式で保存するコードを追加してみます。
 パレイドVibe coding実践例:RSS記事をOllamaでAI要約してMarkdown化するPythonコード(llama3.1:8b)RSSから記事本文を取得し、Ollama(llama3.1:8b)で要約してMarkdownに整形する最小構成をまとめます。進捗ログ付きで、後からRAG素材として再利用し…
パレイドVibe coding実践例:RSS記事をOllamaでAI要約してMarkdown化するPythonコード(llama3.1:8b)RSSから記事本文を取得し、Ollama(llama3.1:8b)で要約してMarkdownに整形する最小構成をまとめます。進捗ログ付きで、後からRAG素材として再利用し…
 パレイドVibe coding実践例:仕様に基づくリファクタリングと遭遇する問題前回まで、RSSフィードからX投稿のコメント生成をLLMで自動化する取り組みを進めてきました。 今回は、前回立てた方針に沿ってコード管理の準備を進…
パレイドVibe coding実践例:仕様に基づくリファクタリングと遭遇する問題前回まで、RSSフィードからX投稿のコメント生成をLLMで自動化する取り組みを進めてきました。 今回は、前回立てた方針に沿ってコード管理の準備を進…
 パレイドVibe coding実践例: RSSからX投稿コメント自動生成の実装前回までの一連の取り組みで、RSSフィードからX投稿のコメント生成をLLMで自動化するコードをVibe codingで作成しました。 今回は、これまでのコード…
パレイドVibe coding実践例: RSSからX投稿コメント自動生成の実装前回までの一連の取り組みで、RSSフィードからX投稿のコメント生成をLLMで自動化するコードをVibe codingで作成しました。 今回は、これまでのコード…