
こんにちは、パレイド技術部の夏目です。
ACE-Stepとは|ローカルで動く無料・商用可のAI作曲
AIで音楽を作る時代。Suno や Udio などのクラウドサービスが広がる一方で、「クラウドに頼らず、自分のPCで音を生みたい」という声も増えています。
ACE-Step は、そんなニーズに応えるオープンソースのAI作曲モデルです。初回セットアップ後はネット接続なしで動作し、無料・商用利用可(Apache-2.0) という自由度の高さが特徴。個人制作のBGMや映像音楽にもすぐ活用できます。
この記事では、ACE-Stepを最短で導入し、初めてのAI音楽を生成するまで の手順を解説します。なお ACE-Step には版があり、本記事で扱う 本体リポジトリ ace-step/ACE-Step(Apache-2.0) が基本形です。より高速・軽量な 1.5/1.5 XL は別リポジトリ ace-step/ACE-Step-1.5(MIT) で公開され、ComfyUI テンプレートから使うのが手軽です。版ごとの違いや用途別の選び方を先に見渡したい場合は、ACE-Step 完全ガイド(1.0 / 1.5 / 1.5 XL の選び方)もどうぞ。

- 無料・商用可(Apache-2.0)。Web UI / CLI の両対応。
- 短尺(30〜60秒) のBGMが安定。長尺は構造が崩れやすい。
- 歌詞→ボーカル生成に対応(整合はプロンプト/シード/環境に依存)。
- 最短導入:
git clone→pip install -e .→acestep。
事前準備|対応OS・推奨環境・公式リンク
ACE-Step はローカル環境で動作します。実行に必要な環境は次のとおりです。
- OS:Windows / macOS / Linux
- Python:3.10 以上
- GPU:NVIDIA CUDA対応GPUがあれば高速。CPUのみ・Apple Silicon でも動作しますが処理時間は長くなります
- メモリ/VRAM:安定動作の目安は VRAM 8GB 以上(軽量化された 1.5 系はより少ないGPUでも動作報告あり)
依存関係を安全に管理するため、venv などの仮想環境の利用を推奨します。
公式リンク: – GitHub リポジトリ:https://github.com/ace-step/ACE-Step – 公式サイト:https://ace-step.github.io/ – Hugging Face:https://huggingface.co/ACE-Step
インストール手順(Windows / macOS / Linux共通)
ACE-Step は公式 GitHub リポジトリから導入します。操作は3OS共通です。
① リポジトリを取得する
git clone https://github.com/ace-step/ACE-Step.git
cd ACE-Step② 仮想環境を作って依存をインストールする
Python 3.10 以上の仮想環境を用意し、リポジトリをそのままインストールします。
python -m venv .venv
# Windows: .venv\Scripts\activate
# macOS / Linux: source .venv/bin/activate
pip install -e .pip install -e . で必要なライブラリ(PyTorch ほか)がまとめて入ります。PyTorch は環境に応じた版が選ばれます。
③ 起動する(モデルは自動ダウンロード)
acestep --port 7865初回起動時、モデルの重みが ~/.cache/ace-step/checkpoints に自動ダウンロードされます(保存先を変えたい場合は --checkpoint_path /path/to/dir を指定)。数GBあるため、初回はネットワーク接続が必要です。
起動すると次のようなURLが表示されます。
Running on local URL: http://127.0.0.1:7865/ブラウザで http://127.0.0.1:7865/ を開くと Web UI(Gradio)が立ち上がります。
補足:GPUを明示したい・共有リンクを出したい場合は
acestep --checkpoint_path /path/to/checkpoint --port 7865 --device_id 0 --share true --bf16 trueのようにオプションを付けられます。
使い方|Web UIで曲を生成する
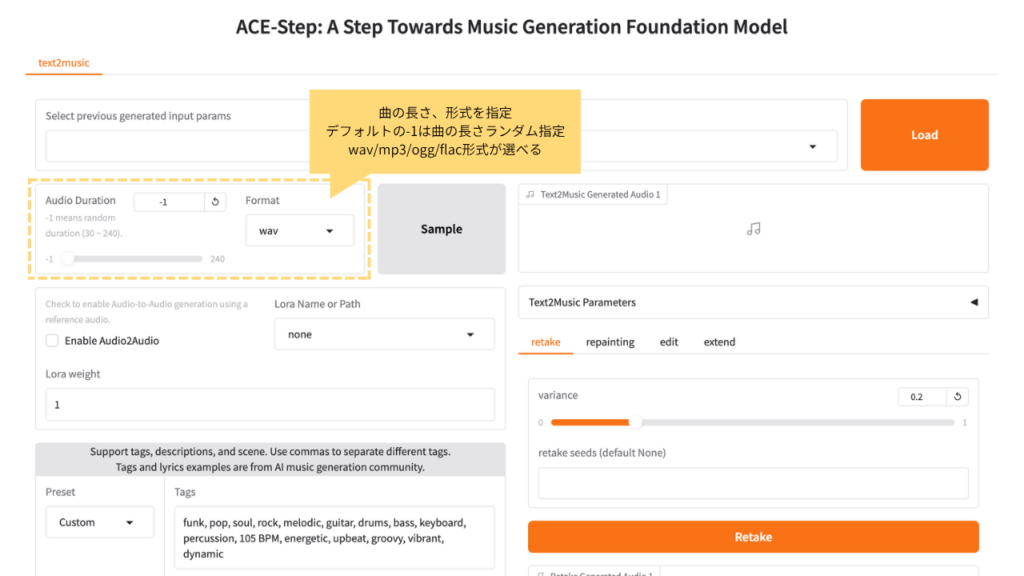
テキスト欄に medieval, fantasy のように曲のイメージを英語タグで入力し、長さ(例:30秒)を指定して「Generate」を押すと、数十秒〜数分で音楽が生成されます。本来はタグを多めに与えたほうが質が上がります。歌詞を入れる場合は lyrics 欄に [verse] [chorus] などの構造タグとともに入力します。
生成後は波形と再生ボタンでその場で試聴でき、wav などの形式で保存できます。
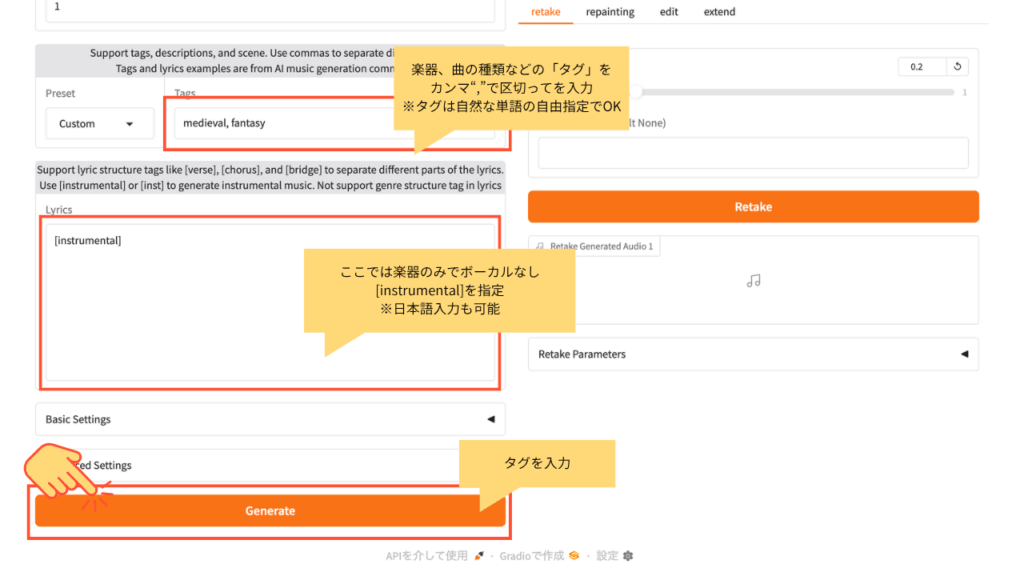
利用のコツ:
– 長時間使うとブラウザのメモリが増えるので、重くなったらタブを開き直す。
– 生成中はタブを閉じずに待機。
– UIが固まったらターミナルで Ctrl + C → 再起動。
出力の傾向とSuno・MusicGenとの比較
ACE-Step は、論文では 拡散生成(Diffusion)+ DCAE +軽量 Transformer を統合した設計とされ、メロディやリズムの一貫性を保ちながら音響ディテールを残せるとされています(参考:ACE-Step 論文)。実利用でも MusicGen 系で見られたパーカッションの途切れやテンポの歪みは少ないという報告が複数ある一方、「やや圧縮感がある」という声もあり、品質はプロンプト・シード・GPU性能に左右されます。
Web UI では最大 240秒(約4分) まで設定できますが、長距離整合性(long-range coherence) が課題で、実用品質を保てるのは1分前後が目安です(長尺は「60秒×複数生成→DAWで連結」が実用的)。
主要モデルとの比較:
| 項目 | ACE-Step | Suno | MusicGen |
|---|---|---|---|
| 実行環境 | ローカル(オフライン可) | クラウド専用 | Web/API/ローカル |
| 最大出力長 | UIで最大240秒 | 最大4分(プラン依存) | 約30秒 |
| 歌詞入力 | 対応(lyrics/構造タグ) | 対応(Customモード) | 基本非対応 |
| 商用利用 | 可(Apache-2.0) | 有料プランで可 | 不可(CC-BY-NC 4.0) |
一次情報:ACE-Step LICENSE / Suno: Commercial vs Non-commercial / MusicGen Docs
総じて ACE-Step は、ローカル実行 × 歌詞条件入力 × 商用可 を一台で満たす点が強みで、短尺・無伴奏のBGM素材生成では高い再現性を示します。歌唱表現や長尺構造は今後の進化に期待、という段階です。
まとめとFAQ
ACE-Step は「自分のPCで動かせる実用的な作曲AI」です。ローカルで動き、無料で、商用利用もでき、改造も可能──その自由度の高さは、AI音楽の“第三の波”とも呼べます。まずは30〜60秒の短尺BGMから試してみてください。
Q1. GPUなし(CPUのみ)でも動く? 動作しますが時間がかかります。まずは30〜60秒の短尺で試すのがおすすめです。
Q2. 推奨スペックは? GPU利用時は VRAM 8GB 以上が目安。足りない場合は他アプリを閉じる、長さを短くするなどで対応します。
Q3. 240秒で品質が崩れるのはなぜ? 長距離整合性の限界です。60秒×複数生成→DAWで連結が実用的です。
Q4. バージョンの違いは? 1.0 → 1.5(高速化・軽量化)→ 1.5 XL(大型・多言語)と進化しています。版の比較は下記の記事にまとめています。
Q5. 商用利用は可能? ACE-Step は Apache-2.0 で配布されており商用可です。ただし生成物に使う外部素材のライセンスは別途確認してください。
 パレイドACE-Step 1.5とは?1.0との違いを実測|2〜10秒/曲・4GB GPU対応・ComfyUI導入こんにちは、パレイド技術部の夏目です。 2026年2月3日に、ACE-Step 1.5が発表されました。 https://ace-step.github.io/…
パレイドACE-Step 1.5とは?1.0との違いを実測|2〜10秒/曲・4GB GPU対応・ComfyUI導入こんにちは、パレイド技術部の夏目です。 2026年2月3日に、ACE-Step 1.5が発表されました。 https://ace-step.github.io/…
 パレイド商用利用OKの音楽生成AI「ACE-Step 1.5 XL」を試してみた|Suno v5超えは本当か?こんにちは、パレイド技術部の夏目です。 オープンソースの音楽生成 AI「ACE-Step 1.5 XL」が MIT ライセンスで公開されました。ベンチマークでは…
パレイド商用利用OKの音楽生成AI「ACE-Step 1.5 XL」を試してみた|Suno v5超えは本当か?こんにちは、パレイド技術部の夏目です。 オープンソースの音楽生成 AI「ACE-Step 1.5 XL」が MIT ライセンスで公開されました。ベンチマークでは…
 パレイド無料でここまで!言葉が音楽になるAI作曲を体験 Suno AI入門この記事のポイント(30秒で要点) 登録→プロンプト→数分で歌入りの曲が完成(1回で2曲生成) 無料枠は1日50クレジット補充、生成時に消費/ダウンロ…
パレイド無料でここまで!言葉が音楽になるAI作曲を体験 Suno AI入門この記事のポイント(30秒で要点) 登録→プロンプト→数分で歌入りの曲が完成(1回で2曲生成) 無料枠は1日50クレジット補充、生成時に消費/ダウンロ…
-300x158.png) パレイドChatGPTに聞きながら試した:ローカルで音楽を生成するには(1週間検証記)🎵 ChatGPTに聞きながら、ローカルAI音楽生成を1週間試した記録(2025年10月) 2025年10月時点で、ChatGPTに「ローカルで…
パレイドChatGPTに聞きながら試した:ローカルで音楽を生成するには(1週間検証記)🎵 ChatGPTに聞きながら、ローカルAI音楽生成を1週間試した記録(2025年10月) 2025年10月時点で、ChatGPTに「ローカルで…