
こんにちは、パレイド技術部の橘です。
ここまで 4 回かけて、Family BASIC マニュアルを LLM 向けに再構造化する設計と実作業を たどってきました。引用ベースのスキーマ設計、Vision LLM での OCR、マニュアル外の事実の 発掘。
 パレイドLLMのためのFamily BASICリファレンス(4)|マニュアルに書いていない記法こんにちは、パレイド技術部の橘です。 前回 (第 3 回) は、Claude Vision で 600dpi マニュアルを起こすワークフローの話でした。 46 …
パレイドLLMのためのFamily BASICリファレンス(4)|マニュアルに書いていない記法こんにちは、パレイド技術部の橘です。 前回 (第 3 回) は、Claude Vision で 600dpi マニュアルを起こすワークフローの話でした。 46 …
リファレンスが揃った今、本来の目的に立ち返ります。結局、LLM はファミベでコードを 書けるようになったのか?
最終回は、完成したリファレンスを system prompt に投入して、Claude とローカル LLM 群に コード課題を解かせるベンチマークです。
ベンチマークの設計
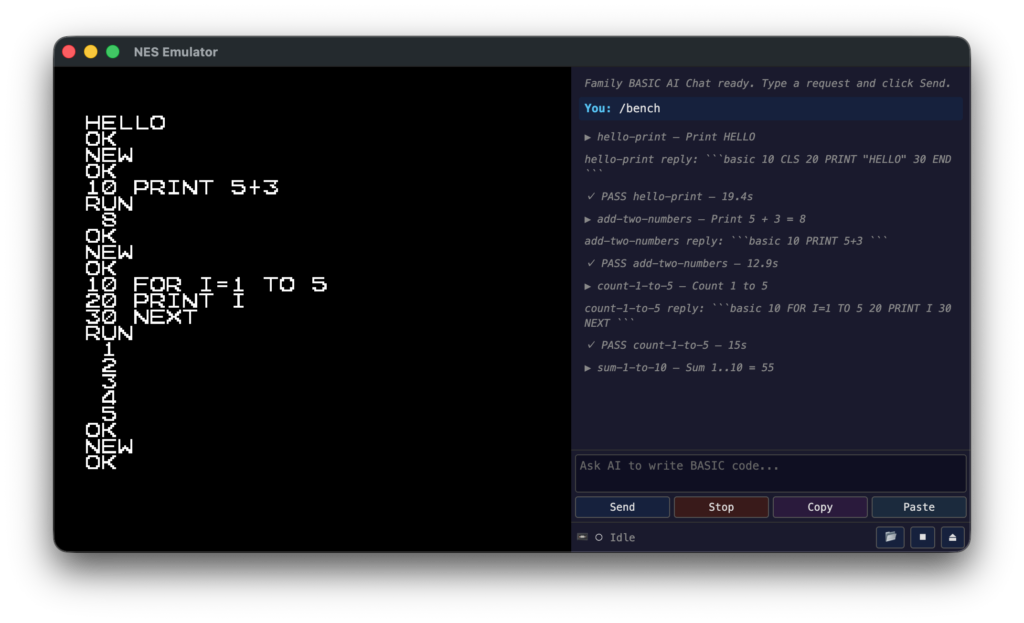
課題セット (8 題)
ファミベの 4 系統を 8 題でカバーします。
- 文字表示 (trivial 5 題):
hello-print(画面に HELLO) /add-two-numbers(5+3=8) /count-1-to-5(FOR-NEXT) /sum-1-to-10(累積、=55) /primes-under-20(素数列挙、MOD) - スプライト 1 題:
sprite-show-anywhere—SPRITE ON+DEF SPRITEで何か 1 つ表示 - サウンド 1 題:
play-melody—PLAYで C-D-E-F-G の 5 音 - コントローラ 1 題:
controller-a-button—STRIG(0)で A ボタン押下を検出し HIT 表示
出力コードを nesemu の headless ハーネスで流し、画面 (nametable → ASCII) / OAM 64 件 (位置・タイル ID) / APU パルスチャンネル (有効時間・周波数の集合) / 標準コントローラ pad (テスト中に A 押下を inject) の 4 系統で自動評価します。
評価軸
| 軸 | 内容 | 自動評価 |
|---|---|---|
| 構文 | ファミベでパース通るか、エラー数 | ◯ |
| 動作 | 意図通りに動くか (画面ハッシュ / 音声 FFT) | ◯ |
| 流儀 | 変数 2 文字、行番号、? 略記、' コメント等 |
△ (静的解析) |
| 密度 | 制約下でどれだけ短く書けるか (行数 / バイト数) | ◯ |
「流儀」だけは部分的に静的解析、残りは完全自動化できる設計にしました。
比較対象モデル
クラウド LLM: – Claude 4.7 (Opus) — 本リファレンスの作成にも使ったベースモデル
ローカル LLM (Apple M シリーズ + 32GB RAM 環境を想定): – Qwen 3.5 9B — Alibaba 汎用、CJK 強い、9B 級の現実的ベースライン – gpt-oss 20B — OpenAI のオープンウェイト、MoE、32GB Mac で動く最大級
コード特化候補だった Qwen2.5-Coder 7B (native context 32k で 56k リファ不可) と DeepSeek-Coder V2 16B (32GB Mac で KV cache が CPU/GPU 分割、prompt eval が 34 tok/s 程度に落ち Ollama 5 分 timeout 超過) は、現時点では154KBものリファレンスを読み込ませることができず本ベンチでは断念。詳細は次回 (実測編) で。 8GB や 16GB Mac でも動くリファレンスは今後の宿題です。
すべてに同じ system prompt (リファレンス本体) と同じ user prompt (課題文) を投げます。
期待される観点
ベンチマークの方針として、下記の観点を盛り込みました。
1. リファレンス投入で何が変わるか
第 1 回で見たように、リファレンスなしの Claude は LET を付け NEXT I と書きます。
リファレンスを system prompt に入れたら、それらの誤りは消えるはずです。
「過去の蓄積を、プロンプトとして LLM に読ませる」効果が定量化されるのがこの実験の中核です。
2. ローカル LLM でどこまで追従できるか
クラウド LLM (Claude) は 154KB のリファレンスを丸ごとコンテキストに注入できる。 ローカル LLM は context window と推論速度の制約で範囲が狭まる。観点は 2 つ:
- 同サイズの汎用モデル間の差 — 32GB Mac で実用域に入る Qwen 3.5 9B と gpt-oss 20B (MoE) で、どこまで結果が分かれるか
- 日本語ドキュメント耐性 — リファレンス本体が日本語なので、英語特化モデルは そもそも読めない可能性
3. マイナー言語 × 制約環境という空き地
ローカル LLM ベンチは Python / C++ / Web 系の課題が中心で、1980 年代の独自方言で
2KB 制約という課題セットは、現存するベンチマークにほぼ存在しません。
本実験の素材自体が、LLM の新しい可能性を開く可能性があります。
おわりに — 1980 年代の言語仕様を 2026 年の AI に届かせる
リファレンス資料を作る作業は地味でしたが、完成して気づいたことが一つあります。 この資料は、1984 年に Family BASIC を手にして「何か作りたかったけど作りきれなかった」 人たちに向けた AI の可能性 だったのかもしれない、と。
マニュアルは持っている。記憶もある。だが手は動かなくなった、あるいは時間が足りなかった、 そういう人たちの手元にもう一度ファミベを置く方法として、AI に書かせるという選択肢が ある。それを可能にする小さな部品の一つが、本連載で作ったリファレンスでした。
実測結果は次回・実測編で。ローカル LLM のスコアが思いの外低かったら、その差は 「クラウド LLM が背負ってくれている言語的常識の重さ」を示すデータになります。
実機で観察した命令の一覧は、ファミリーベーシック 命令辞典 に構文・実機挙動・例つきでまとめています(連載全20回の総索引は 完全リファレンス)。