

短いサウンドから世界は変わります。Stable Audio Openは、テキストを手がかりに44.1kHz・最大約47秒のステレオ音を生成できるStability AIのオープンウェイトモデルです。研究・検証に開かれつつ、現場のSFX(効果音)やドラムループ、環境音づくりを素早く回すための実用性も備えています。
この記事では、何ができるか/導入方法/使いどころ/ライセンスの勘所までを一気に紹介します。
Stable Audio Openとは(3行で)
- 短尺の音素材生成に最適化されたテキスト→オーディオモデル(Stability AI製)です。
- 44.1kHzステレオ/最大約47秒を生成できます。ドラム・SE・環境音などが得意です。
- オープンウェイト配布のためローカル実行が可能です。軽量版はARM CPUのみでも動作します。
2025年にはARM CPUオンデバイス向けの軽量版(Stable Audio Open Small)も登場し、スマホ単体でも高速なサウンド生成が可能になりました。
主な特徴とユースケース
Stable Audio Openは、UIクリック音や通知音、ブランディングSE、フォーリー(足音、紙の擦れ)などのサウンドデザインに適しています。
ドラムパターンやベースリフ、アンビエントパッドなどのループ素材も素早く量産でき、DAWに並べて発展させやすいのが特徴です。映像やゲームBGMの“土台”となる30〜47秒の短い下敷きを量産し、編集で磨くワークフローにも向いています。さらに、テキスト条件付きの音響生成をDiT + オートエンコーダで体験・解析できるため、研究や教材用途にも活用できます。
※本モデルは短いサンプルや効果音の生成に最適化されており、長尺の楽曲や歌唱ボーカルの生成には適していません。短尺×反復活用を基本戦略にすると成果が出やすいです。
モデル仕様とアーキテクチャ概要
本モデルはステレオ・44.1kHz・最大約47秒の可変長出力に対応しています。
テキスト埋め込み(T5系)による条件付けを行い、生成コアはDiT(Transformer系拡散)とオートエンコーダの組み合わせです。研究論文ではCreative Commons系データで訓練されたことが明記されており、軽量版(Small)は約341MパラメータでARM CPUオンデバイスでも約11秒の生成が可能です。
ライセンスと商用利用の勘所
本モデルの公式配布プラットフォームはHugging Faceです。Stability AIがモデルを開発・公開し、Hugging Faceが配布・管理を担っています。利用者はHugging Face経由でモデルのダウンロードや規約同意、トークン発行を行います。
配布はStability AI Community License系です。個人や中小規模の商用利用は許容されますが、一定規模以上の売上やエンタープライズ用途では別途契約が必要になる場合があります。生成物の著作権や権利処理は利用者側の責任範囲となるため、公序良俗や権利侵害の回避は必須です。
※公開前にモデルとサービスの利用規約を再確認してください。案件規模や配信先(アプリ/ゲーム/広告)で要件が変わります。
✅ Stable Audio Open 利用時の判断ポイント(Community License)
個人利用も商用利用も、下記をすべて満たす場合は問題ありません。
2025年10月現在の状況であり、必ず最新情報を確認してください。
| 項目 | 内容 | OKライン |
|---|---|---|
| 収益規模 | 年間売上が 100万USD未満 | ✅ 同意可/超える場合はEnterprise契約 |
| 利用形態 | モデルを組み込む/生成音を配布する | ✅ 配布OK(要ライセンス表記) |
| 表記義務 | “Powered by Stability AI”+ライセンス文を明示 | ✅ 表示できる体制がある |
| 生成物の扱い | 音源・楽曲を公開/販売する | ✅ 可能(著作権は利用者に帰属) |
| 禁止行為 | 出力を使って基盤モデルを再学習する | 🚫 不可 |
| 登録義務 | 商用利用の場合、Stability AIに登録 | ✅ 済ませれば問題なし |
ローカル導入(macOS/Windows)と最小実行例
本モデルは「Pythonライブラリ(stable-audio-toolsやdiffusers等)経由での呼び出し」が前提です。スタンドアロンの実行バイナリやGUIアプリは公式から提供されていません。
Python 3.10+、GPU推奨。Apple Silicon(M1/M2/M3)やCPUのみの環境でも動作しますが、生成に時間がかかります。
Stable Audio OpenのモデルファイルをPythonツールやAPI経由でダウンロード・利用するには、Hugging Faceのモデルページで「利用規約への同意」と「アクセストークンの発行」が必要です(Web UIでの閲覧のみなら不要)。
このトークン発行はHuggin Face上で行います。「Read」権限で十分ですので、必ずアカウント作成・ログイン・トークン発行手続きを済ませておきます。

モデルの利用申請について
Stable Audio Openのモデルは「ゲート付きリポジトリ(Gated Repo)」となっており、Hugging Faceアカウントでの「利用のための連絡先共有・同意」が必要です。
まずモデルページにアクセスします。
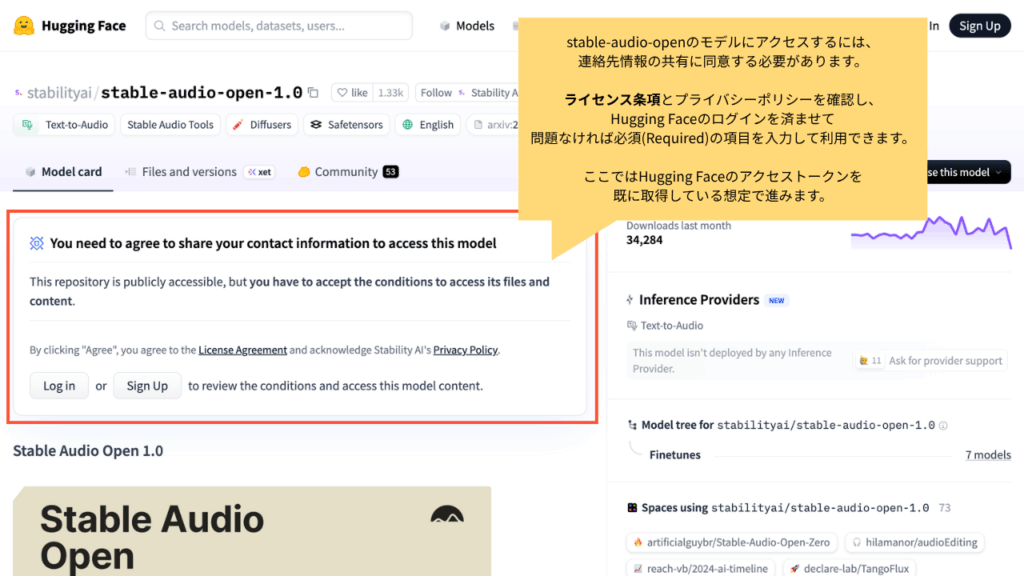
Hugging Faceにログインを済ませると、許諾のための入力画面に移ります。
必須項目を入力し、利用規約に同意します。


手続きが完了すると、アクセスが許可されていることが確認できます。
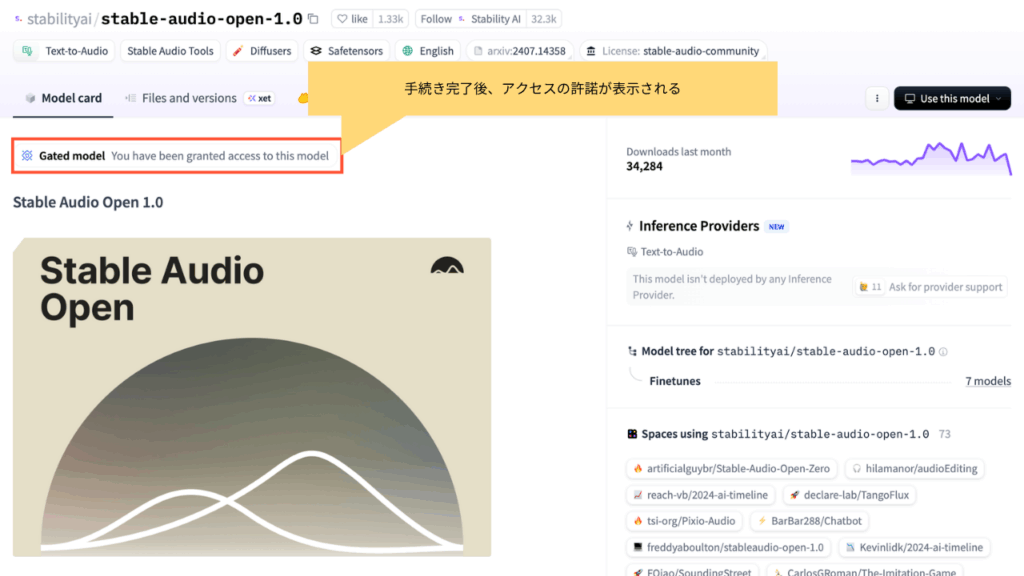
手続きが完了していない場合、途中でエラー(アクセス拒否)が発生します。必ず事前に済ませてください。
1) 仮想環境の作成
利用には様々なモジュールの導入が必要となるため、仮想環境の作成を推奨します。
macOS / Linux(zsh想定)
python -m venv .venv
source .venv/bin/activateWindows(PowerShell)
py -m venv .venv
..venv\Scripts\Activate.ps12) パッケージのインストール
仮想環境を有効化した状態で以下を実行します。
# pipも念の為最新化
$ pip install --upgrade pip
# CUDA環境は公式indexでCUDA版指定/Apple Siliconはpip公式版
$ pip install torch torchvision torchaudio
$ pip install diffusers accelerate transformers soundfile
$ pip install stable-audio-tools huggingface_hub
# torchaudio.saveでWAV保存する場合はtorchcodecも必須
$ pip install torchcodec3) Hugging Faceログイン
Hugging Faceからモデル等をダウンロードするため、アクセストークンを使いログイン状態とします。
$ hf auth login
... (中略)
Enter your token (input will not be visible):
# ここに発行済みのトークン(例: hf_...)を貼り付けてEnter。入力内容は見えません。
Add token as git credential? (Y/n) n
Token is valid (permission: read).
Your token has been saved to /Users/yourname/.huggingface/token成功すると「Token is valid」などと表示され、以降はPythonツールから自動的に認証されます。
補足:「Add token as git credential? (Y/n)」と表示された場合、
- Y(yes): Hugging Faceのリポジトリをgit clone等で操作する際にもこのトークンを使う
- n(no): PythonツールやAPIのみで認証。通常はこちらでOK
Stable Audio Openの利用だけなら「n」で問題ありません。
⚠️ huggingface-cli loginを利用する説明が多く見られますが、2024年10月以降は非推奨(deprecated)となっており、今後はhf auth loginコマンドは推奨とされています。旧コマンド(huggingface-cli login)でも動作しますが、今後は新コマンドを使いましょう。
4) サンプル生成
下記のコードをPythonで実行します。
import torch
import torchaudio
from einops import rearrange
from stable_audio_tools import get_pretrained_model
from stable_audio_tools.inference.generation import generate_diffusion_cond
device = "cuda" if torch.cuda.is_available() else "cpu"
model, model_config = get_pretrained_model("stabilityai/stable-audio-open-1.0")
sample_rate = model_config["sample_rate"]
sample_size = model_config["sample_size"]
model = model.to(device)
conditioning = [{
"prompt": "128 BPM tech house drum loop",
"seconds_start": 0,
"seconds_total": 30
}]
with torch.no_grad():
output = generate_diffusion_cond(
model,
steps=100, # 公式サンプル値
cfg_scale=7, # 公式サンプル値
conditioning=conditioning,
sample_size=sample_size,
sigma_min=0.3, # 公式サンプル値
sigma_max=500, # 公式サンプル値
sampler_type="dpmpp-3m-sde", # 公式サンプル値
device=device
)
output = rearrange(output, "b d n -> d (b n)")
output = output.to(torch.float32).div(torch.max(torch.abs(output))).clamp(-1, 1).mul(32767).to(torch.int16).cpu()
torchaudio.save("output.wav", output, sample_rate)
TIP:最初はsteps=20〜30、cfg_scale=5〜8あたりから始めてください。破綻した場合はcfg_scaleを下げるか、プロンプトを具体化すると安定します。
出力例
下記は Stable Audio Open によって生成したサンプルです。
プロンプトと15秒・20秒等を指定して出力し、ファイルは無音部分をトリミングしています。
ocean waves crashing on beach, seagulls in distance
(和訳: 海岸に打ち寄せる波の音、遠くで鳴くカモメの声)
heavy rain on roof, thunder in distance
(和訳: 屋根を叩く激しい雨の音、遠くで鳴る雷の音)
crackling campfire, wood burning
(和訳: パチパチと音を立てる焚き火、燃える木の音)
forest ambience, birds chirping, gentle breeze through trees
(和訳: 森の雰囲気、さえずる鳥たち、木々を抜ける穏やかな風)
urban street ambience, distant traffic, footsteps
(和訳: 街の環境音、遠くを走る車の音、歩く足音)
実用レシピ:欲しい音を引き出すプロンプト術
一般的な生成AI同様、プロンプト指示を少しずつ変えて反復生成→選別→編集が前提となります。
EQ/コンプ/ノイズ処理は他に外部のDAWを組み合わせると良いでしょう。
音源+質感+空間を並べます。
例)“wooden door creak, close-mic, dry room, short tail”テンポと役割を明記します。
例)“120bpm drum loop, punchy kick, tight hi-hats, minimal”- negative promptとして禁止&抑制ワードを与えて制御します。
例)“no vocals, no melody, focus on percussive texture”
品質を上げるパラメータの考え方
- steps:上げるほど滑らかですが遅くなります。20→40で差分を評価すると無駄がありません。
- cfg_scale:高いほどプロンプト忠実ですが破綻しやすいです。5–8が無難です。
- 秒数:長くするほど難度が上がります。まず10–20秒で方向性を決めてください。
- プロンプト:素材名+形容詞+空間/演奏の三層構成が安定します。
よくある質問(FAQ)
Q1. 歌入りの長尺楽曲は作れますか?
→ 想定外です。短尺のSFXやループ主体で使い、DAWで編集が現実的です。
Q2. CPUだけで動きますか?
→ 可能ですが時間がかかります。品質検証はCPUでも、量産はGPUをおすすめします。
Q3. 商用で使えますか?
→ Community Licenseの範囲であれば可能です。
売上規模や用途によっては別契約が必要になる場合があり、利用前に最新規約をご確認ください。
Q4. 英語以外のプロンプトはどうですか?
→ 英語最適化が前提です。英語キーワード主+日本語補足での記述をおすすめします。
Q5. 47秒以上を生成したいです。
→ 外部で連結・編集・ループ化で対応となります。段落的な楽曲構成はDAW側で作る前提で設計してください。
Q6. どのくらいのVRAMが必要ですか?
→ モデルや設定で変動します。まずは短秒数×低ステップで試し、必要に応じてGPUメモリを確保してください。
まとめ
Stable Audio Openは短尺音素材の量産に最適です。ローカル実行により再現性とコストをコントロールしやすく、Small版によってオンデバイスの可能性も広がりました。ライセンスと権利処理は常に最新を確認し、案件規模に応じて運用してください。
参考リンク/出典
- Stability AI公式アナウンス(Stable Audio Open, 2024-06-05)
- モデル配布ページ(Hugging Face)
-160x90.png)



