

少し前までは特別な操作が必要でしたが、今では画像からテキストをコピーできるのが当たり前になりました。
例えば macOS では Vision フレームワークが提供されており、Finder や Safari などからOS標準機能としてOCRを利用できます。
ショートカットアプリでのOCR
OS標準のOCR機能を処理に組み込む場合は、Swift などから Vision フレームワークを直接呼び出す必要があります。
一方、簡易的な用途であれば、ショートカットアプリの「画像からテキストを抽出」アクションを使うことで手軽にOCRを利用できます。
このアクションは画像を入力として受け取ります。今回はスクリーンショットと組み合わせて動作を確認しました。
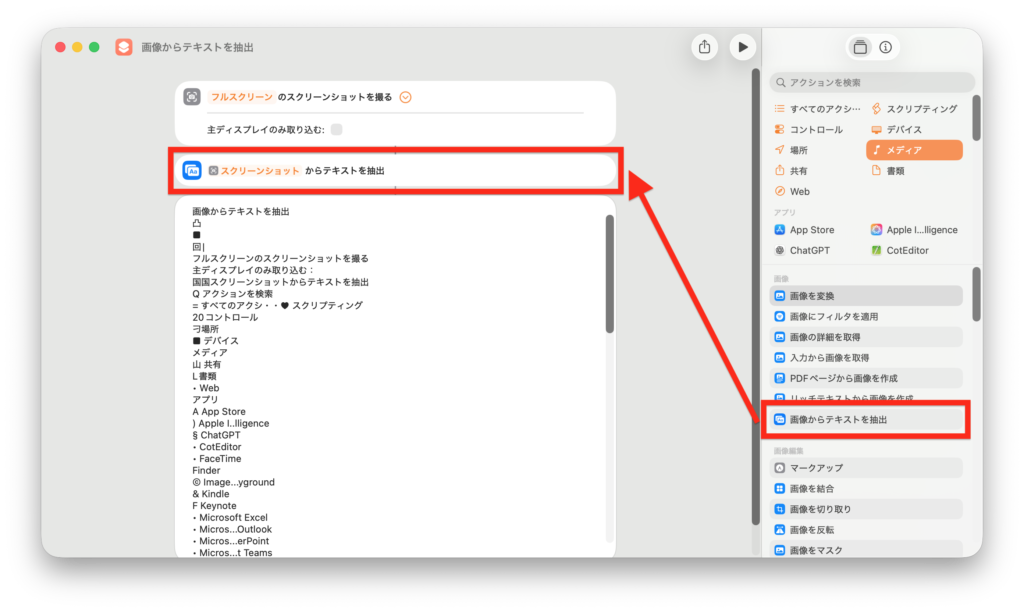
アイコンが文字として誤認識されたり、「Microsoft」のような英単語が崩れて認識されるケースが見られました。特に日本語と英語が混在する文章では、精度がやや不安定になるようです。
一方で、フォントの書体バリエーションや装飾されたロゴ風の文字も、簡単な検証の範囲では一定程度読み取れていました。Tesseract や EasyOCR では判別が難しいゲーム画面の文字にも追従する場面があります。
なお、抽出されるテキストの順序は必ずしも画面表示順とは一致しません。Vision フレームワークが bounding box(bbox)単位で解析し、内部的に読順を推定しているためと考えられます。概ね直感的な順序になりますが、順番に依存する自動化処理は避けたほうが安全です。
応用例
一見すると用途が限定的に思えるOCRですが、ショートカットアプリと組み合わせることで実用性が大きく広がります。特に、自動処理の「結果確認」において有効です。
たとえばショートカットからアプリを起動し、何らかの処理を実行したものの、APIやログとして結果を取得できないケースがあります。そのような場合でも、画面上に表示された数値やテキストをOCRで読み取り、処理結果として取得できます。タイミング計測や状態判定など、UIしか出力手段がないアプリとの連携にも応用可能です。
さらに、抽出したテキストをLLMに渡して整形・要約させたり、異常値の検出や補助情報の付加に活用することもできます。VisionベースのOCRは精度に限界があるとはいえ、画面操作を前提とした自動化においては、比較的安定した実用的な手段と言えるでしょう。
まとめ
macOSでは、Visionフレームワークを通じて高精度なOCR機能が標準提供されています。FinderやSafariからのコピーはもちろん、ショートカットアプリ経由でも手軽に利用できます。
一方で、読順や文字認識の精度にはばらつきがあり、特に日本語と英語が混在する画面や装飾文字では誤認識が発生することもあります。自動処理に組み込む場合は、順序や精度に依存しすぎない設計が重要です。
 パレイドRAGとは何か:LLM単体の限界を超えて「自分のデータ」で答えさせる方法RAG(Retrieval Augmented Generation)は、LLMの外に知識ベースを置き、必要な情報を検索してから回答させる仕組みです。LLM単体の弱点(知識が固定…
パレイドRAGとは何か:LLM単体の限界を超えて「自分のデータ」で答えさせる方法RAG(Retrieval Augmented Generation)は、LLMの外に知識ベースを置き、必要な情報を検索してから回答させる仕組みです。LLM単体の弱点(知識が固定…
 パレイド嗜好化するToDo管理(1) ToDo管理にAIを導入したいこんにちは。パレイド思想部です。 趣味に充てられる時間は、日によって大きく変わります。忙しい時期を抜けた頃には、何をやっていたのか思い出せな…
パレイド嗜好化するToDo管理(1) ToDo管理にAIを導入したいこんにちは。パレイド思想部です。 趣味に充てられる時間は、日によって大きく変わります。忙しい時期を抜けた頃には、何をやっていたのか思い出せな…
 パレイドAIとエディタの融合:Cursor導入方法Cursorは、AIを標準搭載したコードエディタです。 従来のエディタのように「人がコードを書き、AIは拡張機能として補助する」という関係ではなく、AI…
パレイドAIとエディタの融合:Cursor導入方法Cursorは、AIを標準搭載したコードエディタです。 従来のエディタのように「人がコードを書き、AIは拡張機能として補助する」という関係ではなく、AI…