
こんにちは、パレイド思想部です。
前回は3フェーズパイプラインの全体像を説明しました。
今回は、インペイントの精度を左右するマスク生成の仕組みを掘り下げます。MediaPipe の顔ランドマーク検出と、ポリゴンベースのマスク生成、フェザリングによる境界処理です。
本記事はローカル LLM による自動執筆パイプラインで生成されました。現段階ではクラウド AI(Claude 等)の補助や人間の編集が介在していますが、pareido.jp では最終的に AI が自律的にコンテンツを制作できる仕組みの構築を目指しています。
AI は雑に使うと雑な結果しか出ない
画像生成 AI に対する誤解のひとつに「プロンプトさえ書けば綺麗な絵が出る」があります。実際にはそうではなく、入力の精度が出力の精度を決めます。
インペイントにおける「入力」はプロンプトだけではありません。マスク——つまり「画像のどの部分を書き換えるか」の指定——が、結果を最も大きく左右します。Stable Diffusion系 の GUI でマスクを手描きすることもできますが、毎回手動で描くのは大変ですし、18枚の表情差分すべてに一貫したマスクを手描きするのは現実的ではありません。
パイプラインのコードは、顔のランドマーク検出から自動的にマスクを生成します。目の楕円、口の楕円、顔全体の領域をピクセル単位で計算し、境界のぼかし処理まで含めて再現性のある結果を出します。ユーザーが「どこをどうマスクすればいいか」を考える必要はありません。
なぜマスクが重要なのか
インペイントは「マスクで指定した領域だけを再生成する」技術です。マスクの品質がそのまま出力品質に直結します。
- マスクが小さすぎる → 表情が変わりきらない
- マスクが大きすぎる → 顔の輪郭や髪型まで別人のように変わってしまう
- マスク境界がシャープ → インペイント領域と元画像の境目が目立つ
理想的なマスクは、変えたい領域だけを正確にカバーし、境界がなだらかに減衰するものです。
MediaPipe の68点ランドマーク
Google MediaPipe の Face Mesh は、AIが顔画像を認識し、「顔」のパーツを68点のランドマークとして検出します。このうち、アバター生成に使うのは主に以下の領域です。
- 目(左右) — 各6点(上瞼・下瞼の輪郭)
- 眉(左右) — 各5点
- 口 — 外唇12点 + 内唇8点
- 顔輪郭 — 17点(顎〜こめかみ)
- 鼻 — 9点
これらのランドマーク座標から、各パーツの領域をポリゴンとして構築します。
ポリゴンベースでの目・眉のマスク生成
単純な矩形マスクでは、顔の傾きや形状に対応できません。目と眉を表すランドマークの座標群から、両者を含んだ凸包(convex hull)を計算し、さらに 角度を決めて(PCA で主軸方向を求めて)楕円にフィッティングします。
# 口のランドマーク12点から楕円マスクを生成
points = get_mouth_landmarks(face_mesh_result)
hull = cv2.convexHull(points)
ellipse = cv2.fitEllipse(hull) # 中心, 軸長, 回転角
# 楕円を expand_ratio 分だけ拡大
center, axes, angle = ellipse
axes = (axes[0] * expand_ratio, axes[1] * expand_ratio)
# マスク画像に描画
mask = np.zeros((h, w), dtype=np.uint8)
cv2.ellipse(mask, (center, axes, angle), 255, -1)この方式の利点は、顔がやや傾いていても楕円がそれに追従する点です。軸に沿わない(non-axis-aligned)楕円なので、少し横向きで回転した顔にも対応できます。ここで目や眉がしっかり領域に入っていないと、目を閉じるインペイントの成功率が大きく下がります。


スタイル別の3層チューニング
MediaPipe は実写の人間の顔で学習されたモデルです。そのため、アニメやイラストの顔に対しては検出精度が大きく下がります。「同じコードで anime も realistic も処理する」ためには、スタイルに応じた補正を複数の層で入れる必要があります。
実装では、以下の3層でスタイル別の調整を行っています。
層1: 検出信頼度の閾値
MediaPipe に渡す min_face_detection_confidence をスタイルごとに変えています。
| スタイル | 検出閾値 |
|---|---|
| anime | 0.25 |
| illustration | 0.30 |
| realistic | 0.50 |
アニメ絵は実写と顔の描き方が違うため、MediaPipe の検出スコアが低く出ます。閾値を下げないと「顔が見つからない」と判定されてパイプラインが止まります。
層2: マスク拡大率
MediaPipe のランドマーク座標はスタイルによらず共通ですが、マスクの最適サイズはスタイルごとに異なります。
| パラメータ | anime | illustration | realistic |
|---|---|---|---|
| eye expand_ratio | 0.60 | 0.40 | 0.30 |
| eye expand_up_ratio | 0.80 | 0.60 | 0.40 |
| eye expand_down_ratio | 0.30 | 0.20 | 0.10 |
anime スタイルは目が大きく描かれるため、マスクも広めに取る必要があります。特に上方向の拡大率が大きいのは、アニメキャラの目が縦に大きいためです。また下方向に拡大しすぎると、鼻が含まれ上書きされしまい作画が安定しません。realistic は顔パーツの比率が実写に近いため、狭めで十分です。

層3: 品質チェックのフォールバック
インペイント後の品質チェック(目が閉じているか等)でもスタイル分岐があります。目の変化、特に閉じた目の描画は生成AIが苦手としている表現のようで、チェックの自動化は欲しいところ。
realistic では、MediaPipe のランドマークから EAR(Eye Aspect Ratio:目の縦横比)を計算し、閾値以下なら「閉眼」と判定します。
anime では、そもそも MediaPipe が顔を検出できないケースが発生します。その場合、ランドマークベースの判定を諦めて、ピクセルレベルのコントラスト分析にフォールバックします。目の領域の明暗差が小さければ「閉じている」と推定する方式です。ただし、これはかなり精度が悪く、顔を認識できる画像を改めて準備する方がおすすめです。
MediaPipe は強力なモデルですが、「実写の顔」に最適化されています。アニメ絵に対しては、検出 → マスクサイズ → 品質検証のすべてのステップで精度が落ちます。1箇所だけ補正しても、別のステップで破綻します。3層すべてで調整することで、はじめてアニメ・イラスト・実写を同じパイプラインで扱えるようになります。
 Google for DevelopersFace landmark detection guide | Google AI Edge | Google for Developersai.google.dev
Google for DevelopersFace landmark detection guide | Google AI Edge | Google for Developersai.google.dev
フェザリング(境界のぼかし)
マスクの境界をシャープなまま使うと、インペイント結果に明確な「継ぎ目」が見えます。これを防ぐのがフェザリングです。
# ガウシアンブラーでマスク境界をぼかす
feather_radius = 16 # ピクセル数
mask_feathered = cv2.GaussianBlur(mask, (0, 0), feather_radius)フェザリング半径は8〜24ピクセルが目安です。小さすぎると効果が薄く、大きすぎるとマスク領域が不必要に広がります。
マスク値が0〜255のグラデーションになることで、ComfyUI のインペイントは境界付近で元画像と生成画像をブレンドします。これにより、自然な遷移が実現します。

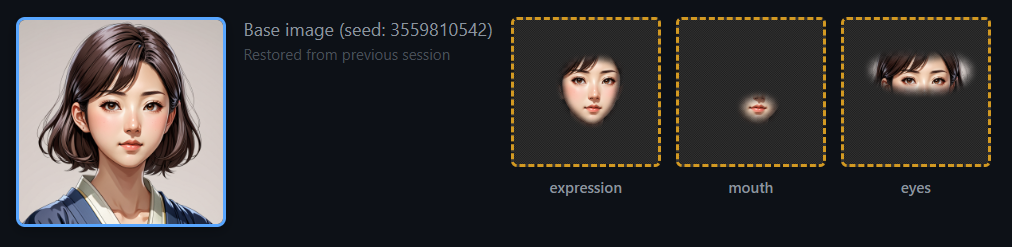
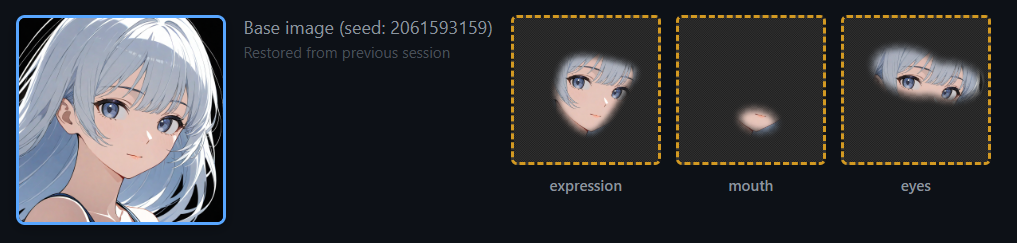
マスクの使い分け
最終的に生成する3種類のマスクの関係を整理します。
expression_mask(顔全体)
├── mouth_mask(口だけ) ← expression の一部
└── eye_mask(目だけ) ← expression の一部
head_mask(頭部全体)
└── expression_mask ← head の一部Phase 2 では expression_mask で顔全体をインペイント。Phase 3 では mouth_mask と eye_mask で部分的にインペイント。head_mask はレイヤー分解(第6回)でも使います。
次回予告
次回は、生成したスプライト群をアニメーション可能な3レイヤー(body / head / face)に分解する仕組みを解説します。Motion PNGTuber として使うための、レイヤー分離と再構成検証です。