
こんにちは、パレイド思想部です。
前回はチェックポイントの比較でモデルを選定しました。
今回は、seed を変えて複数の候補画像を生成し、MediaPipe の顔検出で自動スコアリングして最良の1枚を選ぶ「ガチャシステム」を作ります。
本記事はローカル LLM による自動執筆パイプラインで生成されました。現段階ではクラウド AI(Claude 等)の補助や人間の編集が介在していますが、pareido.jp では最終的に AI が自律的にコンテンツを制作できる仕組みの構築を目指しています。
「ガチャ疲れ」という体験
画像生成 AI を触ったことがある人なら、誰しも経験があるはずです。「生成→微妙→seed 変えてもう一回→まだ微妙→もう一回…」の無限ループ。いわゆる ガチャ疲れです。
同じプロンプト・同じモデルでも、seed が変われば出力は全く違います。良い絵が出るかどうかは運次第。しかも「良い」の判断基準が曖昧なまま目視で選んでいると、何十回も生成した末に「最初のやつが一番良かったかも」という経験すらあります。
ここでの思想は明確です。「良いアバターとは何か」を数値で定義できれば、選定は機械に任せられる。アバター用途なら「顔が正面で、画面に収まっていて、パーツが明瞭」という基準は客観的に定量化できます。このパイプラインのコードが、ガチャの試行錯誤からユーザーを解放します。
1. N枚の候補を異なるseedで一括生成
2. 各候補を品質チェッカーで自動評価
3. スコア最高の1枚を自動選定ガチャの実装
デフォルトでは4候補を生成します。seed は基準値から1000刻みでオフセットします。
candidates = []
for i in range(num_candidates):
seed = base_seed + i * 1000
image = generate_base(workflow, seed=seed)
score = validate_base_image(image)
candidates.append({"seed": seed, "image": image, "score": score})4枚なら生成時間は約2〜4分(1024px、30steps の場合)。GPU メモリに余裕があれば ComfyUI のキュー機能で並列化も可能です。
MediaPipe による顔検出
Google の MediaPipe は、リアルタイム顔検出ライブラリです。68点の顔ランドマーク(目、鼻、口、輪郭)を検出し、confidence スコアを返します。
アバター用途では、以下を評価基準にします。
- 顔が検出できるか(confidence > 閾値)
- 顔の位置とサイズ(フレーム内に収まっているか)
- 正面度合い(左右対称性)
スタイル別の閾値調整
MediaPipe はリアル顔画像用に訓練されているため、スタイルによって検出精度が異なります。
| スタイル | confidence 閾値 | 備考 |
|---|---|---|
| realistic | 0.85 | 高精度で検出可能 |
| illustration | 0.70 | やや不安定 |
| anime | 0.50 | 目が大きすぎると検出失敗もある |
anime スタイルでは閾値を下げる必要がありますが、下げすぎると誤検出(顔でない領域を顔と判定)のリスクが上がります。
品質チェッカーの構成
顔検出だけでなく、複数の品質チェックを組み合わせています。
- 顔検出チェック — 顔が1つ検出されること
- 頭部切れチェック — 頭頂部がフレーム内に収まっていること
- 目の位置チェック — 左右の目の中心がずれていないこと
全チェックをパスした候補の中から、confidence スコアが最も高いものを選定します。全候補が不合格なら、やむを得ず最もスコアが高いものをフォールバックとして採用しますが、ガチャを引き直すほうがおすすめです。
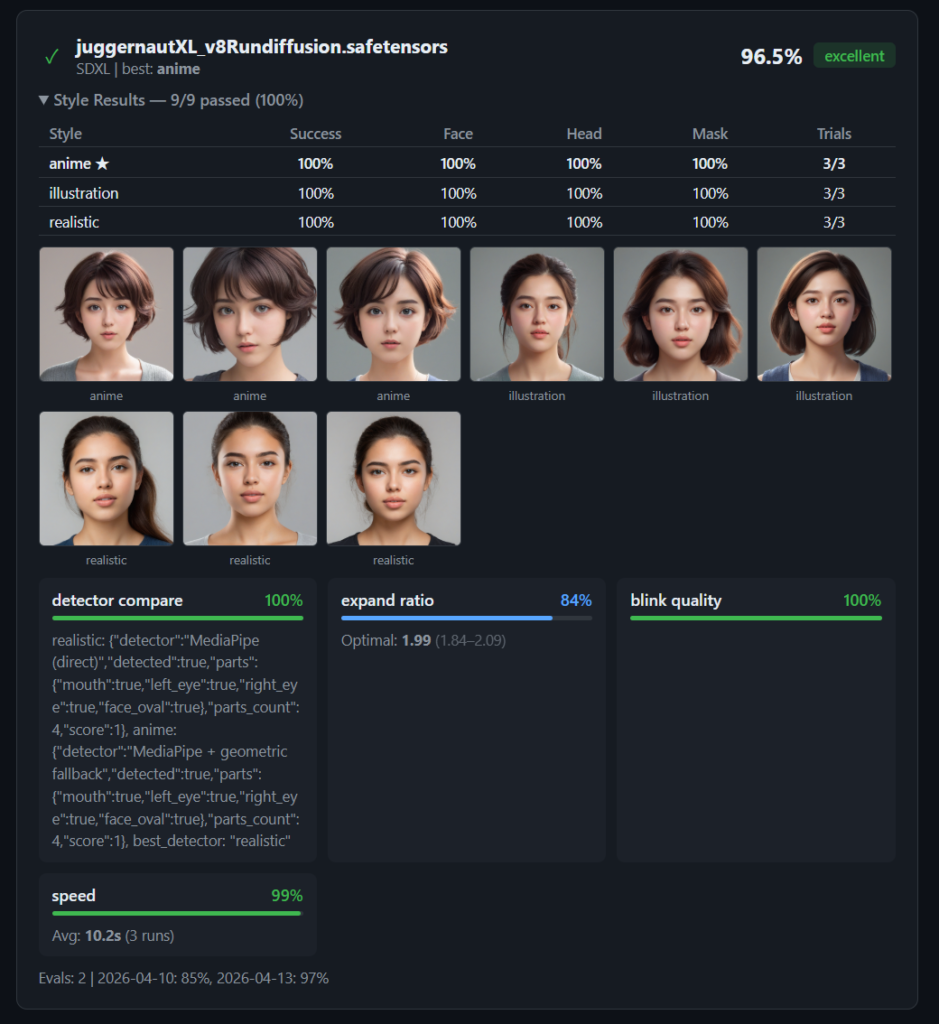
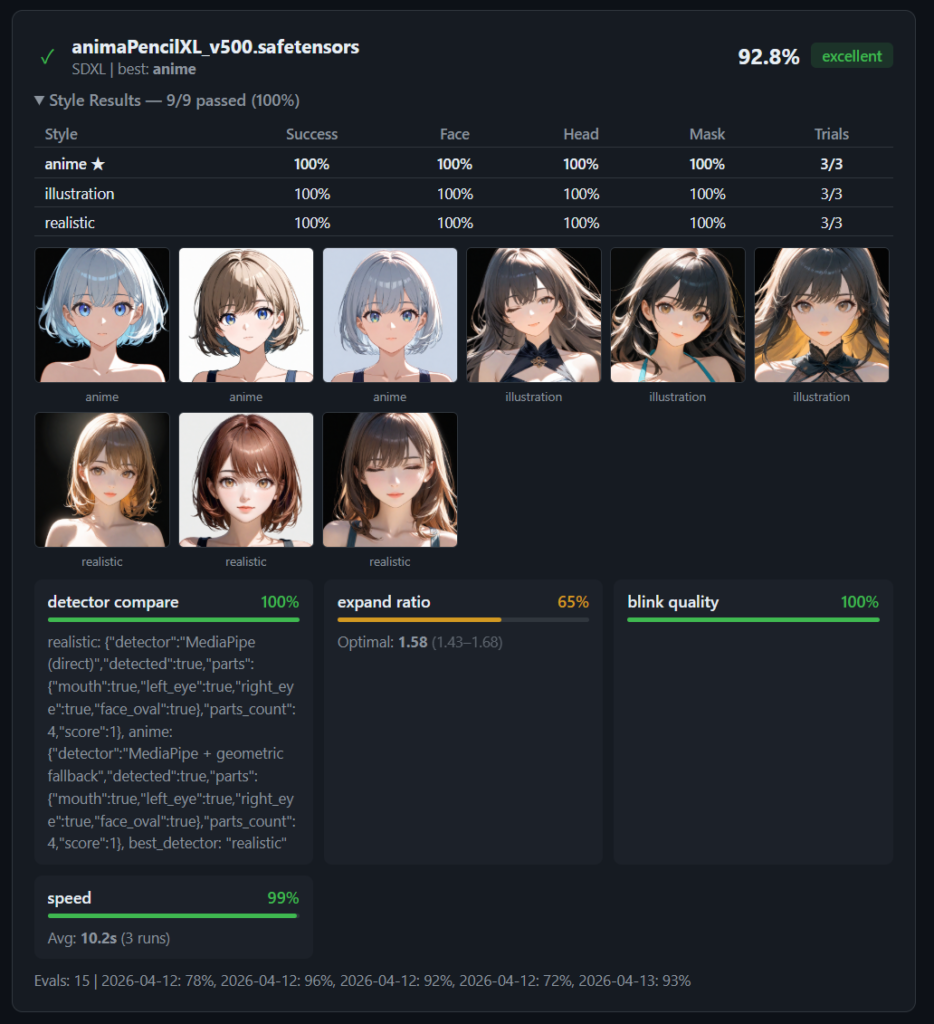
ガチャ結果の保存
選定結果は JSON に保存し、あとから確認・手動変更できるようにしています。
{
"candidates": [
{"seed": 12345, "valid": true, "face_score": 0.92},
{"seed": 13345, "valid": true, "face_score": 0.87},
{"seed": 14345, "valid": false, "face_score": 0.31},
{"seed": 15345, "valid": true, "face_score": 0.89}
],
"selected": 12345
}自動選定に納得がいかない場合は、サムネイル一覧を見て手動で別の候補を選ぶこともできます。
次回予告
ベース画像が決まったところで、次回はいよいよ表情差分の生成に入ります。インペイント機能を使い、1枚のベース画像から6感情×3状態(口閉じ・口開き・瞬き)の18バリアントを自動生成するパイプラインを構築します。