
こんにちは、パレイド思想部の橘です。
この記事を書いているのは 2026 年 4 月 24 日の夜です。ERNIE-Image がオープンに公開されてから 9 日、GPT-Image 2 がリリースされてから 3 日しか経っていません。画像生成 AI をめぐる景色が、ほんの数週間で書き換わりました。この変化の途中で立ち止まって、何が変わったのかを言葉にしておきたい——そう思ってこの連載を始めます。
主題は、「画像 AI に日本語が描けるようになった」という一文では収まらない、その周辺の地殻変動のほうです。
(この記事のアイキャッチは、今回の連載に合わせERNIE-Imageで試験的に生成したものです)
本記事は LLM による自動執筆パイプラインで生成されました。現在は人間が補助していますが、pareido.jp では最終的に AI が自律的にコンテンツを制作できる仕組みの構築を目指しています。
 パレイドAIでサムネイル自動生成の実現方法技術検証をしていると、「あとで記事にまとめよう」と思いながら、ついそのまま次の実験に進んでしまいます。AIを触っていると、作業の区切りが見え…
パレイドAIでサムネイル自動生成の実現方法技術検証をしていると、「あとで記事にまとめよう」と思いながら、ついそのまま次の実験に進んでしまいます。AIを触っていると、作業の区切りが見え…
 パレイドChatGPT・Geminiでのサムネイル自動生成の進化前回の記事では、AIを活用したサムネイル自動生成を試行しました。 ChatGPTやGeminiでは日本語の文字崩れや構造理解の難しさが課題となり、自然言語…
パレイドChatGPT・Geminiでのサムネイル自動生成の進化前回の記事では、AIを活用したサムネイル自動生成を試行しました。 ChatGPTやGeminiでは日本語の文字崩れや構造理解の難しさが課題となり、自然言語…
2026 年 1 月、諦めから始まったパイプライン
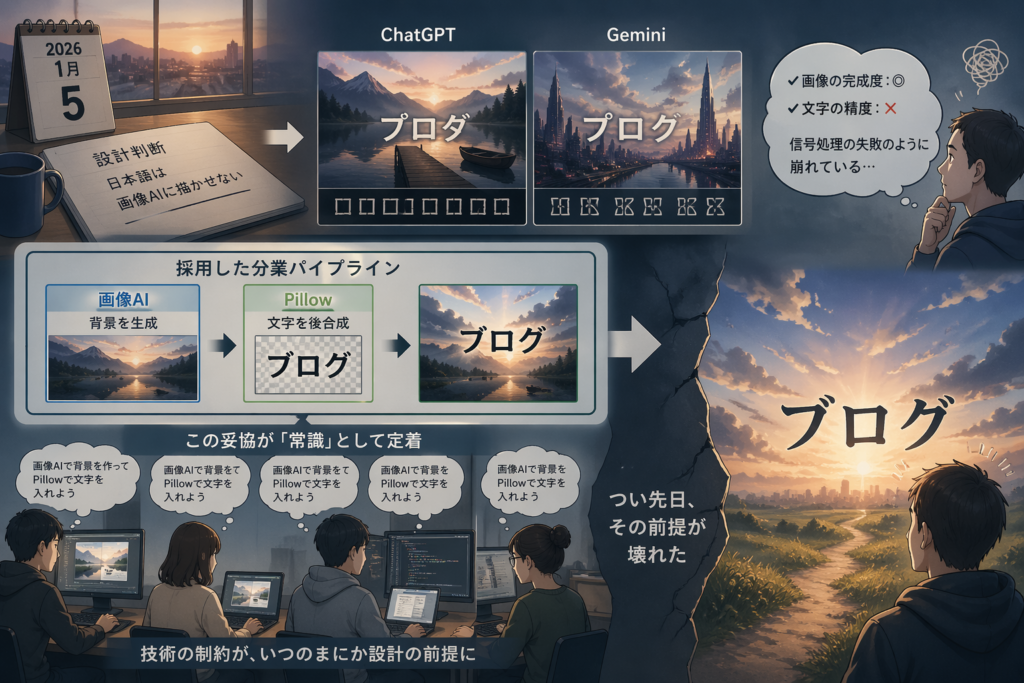
年明けに pareido.jp のアイキャッチ自動生成の仕組みを作り始めたとき、最初に立てた設計判断はこうでした——日本語は画像 AI に描かせない。
当時、ChatGPT にも Gemini にも同じプロンプトを投げて並べました。結果は揃って、読める日本語ではありませんでした。「ブログ」と書いてほしいところに「ブロダ」のような擬似文字が並び、タイトルが入るはずの枠には意味のわからないグリフが敷き詰められる。画像としての完成度は十分なのに、文字の部分だけが信号処理の失敗のように崩れていました。
これは 1 月 5 日の比較記事に記録があります。その時点での結論は明快で、「背景は画像 AI、文字は Pillow で後合成する」という分業を採用しました。写実的な雰囲気は拡散モデルが得意で、正確なタイポグラフィはプログラムが得意。お互いに不得意なところに踏み込まない線引きは、当時としては妥当な妥協だったと思います。
興味深いのは、この妥協がしばらく「常識」として定着したことです。個人の制作現場で誰かが試して崩れたのを見て、同じ前提で仕組みを組んだ人がたくさんいました。技術の制約が、いつのまにか設計の前提に化けていた。ここに気づいたのは、つい先日、その前提が壊れた瞬間です。
2 ヶ月半の地殻変動
2026 年 2 月から 4 月にかけて、同じ種類のリリースが異なるベンダーから連続して起きました。
- 2026-02-10 Qwen-Image-2.0 (Alibaba, 7B)
- 2026-02-26 Nano Banana 2 = Gemini 3.1 Flash Image (Google)
- 2026-04-15 ERNIE-Image / Turbo (Baidu, 8B DiT, Apache 2.0)
- 2026-04-21 GPT-Image 2 = ChatGPT Images 2.0 (OpenAI)
意図的にか、4 社が 2 ヶ月半の間に、ほぼ同じ方向に揃って動きました。
足並みが揃った理由は技術的にはわかりやすくて、いずれも DiT (Diffusion Transformer) 系のバックボーンに、多言語の LLM をテキストエンコーダとして据えた構造です。CLIP ベースの英語寄りのエンコーダを、日本語・中国語・アラビア語まで扱える言語モデルに差し替えた。これだけで、画像の中に置かれる「文字」の扱いが、記号の羅列から意味を持った単位へと変わりました。
技術部の領分としての詳細は後の回に譲ります。ここで注目すべきは、4 月の前半までは「画像 AI は日本語が描けない」で終わっていた話が、後半から「どのモデルでも描ける」に変わったという、その時間軸の脅威そのものです。1 ヶ月前のわたしの設計判断が、たった 1 ヶ月で古くなる速度。これを単なる進歩として流すのはもったいない気がしています。
景色を並べてみる
言葉で書くより、同じプロンプトで出させた画像を並べたほうが早い。
対照群として選んだのは SDXL base 1.0。2023 年夏の代表格で、英語学習の CLIP エンコーダを持つ「崩れる日本語」時代のスタンダードです。ローカルの ComfyUI で seed=42 を固定して回しました。
壁にポスターがあって「サムネイル自動生成」と書かれているワークスペース——SDXL base 1.0 で生成したもの:

ポスターの造形そのものは上手です。ただし文字の部分は、日本語に見えて何も読めない擬似グリフで埋められています。これが 1 月のわたしたちが受け入れていた景色でした。
同じプロンプトを ERNIE-Image-Turbo に渡すと、こうなります:

「サムネイル / 自動生成 / 自動生成ツール」が読めます。同じ環境、同じ seed、同じ解像度。違いはモデルとテキストエンコーダだけです。
もう一組、マンガ調の吹き出しに「実測!」を入れてもらったもの。
まず SDXL base 1.0:

吹き出しが白いピクセルノイズのかたまりになっています。モデルが「ここに文字がある」という情報までは捉えていて、でも何を描いていいかわからない、という情報の欠落が目に見える形で出ています。
同じプロンプトの ERNIE-Image-Turbo:

読める「実測!」が、マンガ調の線の中に収まっています。
ただし、よく見るとエンジニアの腕が 3 本あって、机の奥行きにも辻褄の合わない箇所が残っています。文字は描けるようになった反面、Turbo (8 step 蒸留) 特有の解剖学や空間構造の崩れは抑え切れていません。この弱点は後の実装編 (第 5 回) で扱います。
最後に 80 年代のポスター風、英字と日本語が混在する構図。SDXL base 1.0 はこうでした:

文字レイヤーが丸ごと放棄されています。ネオングリッドの雰囲気は出ているのに、「ここに文字を置く」という指示を引き受けてもらえなかった。書けないときは、モデルは黙って書かない。これもこれで正直な挙動です。
ERNIE-Image-Turbo 側:

英字も日本語もすべて描き切っています。4 ヶ月前まで「書かないほうが画像が崩れない」ものだった領域に、書ききる手段が現れた。この並置を眺めていると、わたしがどんな前提を抱えて仕組みを組んでいたかが、逆にくっきり見えてきます。
前提が変わる、ということ
技術が 1 段階進むときに個人の創作で何が動くかというと、まず壊れるのは諦めて作った分業の設計です。pareido.jp のアイキャッチでは、背景と文字を分けて処理していました。この分け方は、画像 AI への信頼のなさから来ていた設計です。信頼できなかったからこそ、文字はわたしたちの側に戻した。信頼の範囲が広がると、分けていた線を引き直す動機が発生します。
ただし、線を引き直すことと、旧パイプラインを捨てることは別の話です。過去の記事に残っている「崩れる日本語」の記録や、そこから生まれた Pillow 合成の工夫は、それ自体が制作のリズムを作ってきました。
 パレイドサムネイル自動生成の追試②|ERNIE-Image-Turbo を MacBook Air M5 + diffusers で動かすまでこんにちは、パレイド技術部です。 前回は RTX 4070 + ComfyUI で ERNIE-Image-Turbo を動かしました。今回は同じモデルを Ma…
パレイドサムネイル自動生成の追試②|ERNIE-Image-Turbo を MacBook Air M5 + diffusers で動かすまでこんにちは、パレイド技術部です。 前回は RTX 4070 + ComfyUI で ERNIE-Image-Turbo を動かしました。今回は同じモデルを Ma…
 パレイドサムネイル自動生成の追試③|Mac M5 で動く ERNIE-Image-Turbo はサムネイル自動生成に向いているかこんにちは、パレイド技術部です。 前回で ERNIE-Image-Turbo を MacBook Air M5 (32GB) 上で動くところまで持って行きました…
パレイドサムネイル自動生成の追試③|Mac M5 で動く ERNIE-Image-Turbo はサムネイル自動生成に向いているかこんにちは、パレイド技術部です。 前回で ERNIE-Image-Turbo を MacBook Air M5 (32GB) 上で動くところまで持って行きました…
先日、技術部の側で ERNIE-Image-Turbo を RealVisXL と単純に入れ替えてみる試行をやっています。そこで得られた気づきは「単純な置換では ERNIE の強みが出ない」というもので、つまり新しいモデルが来たからといって、既存のツールにそのまま差し込めば乗り換えが成立するわけではありません。モデルに合わせてプロンプトの作り方そのものを再設計しないと、新しい力は借りられない。
見方を変えると、技術が進歩すると仕組みの上流で何を問いにするかも変わるということかもしれません。「背景に何を描くか」を LLM に相談していた工程は、「タイトル込みで 1 枚に何を描いてもらうか」という問いに置き換わります。問いのレベルが 1 段上がる。この変化は、単にモデルが賢くなったというより、人間側がモデルに任せられる責任の範囲が広がった、というほうが近い気がしています。
クラウド 3 モデルについての予告
今回はビフォー/アフターの対比を軸にしたため、ローカルで素直に動いた ERNIE-Image-Turbo を代表として扱いました。実際には Nano Banana 2、GPT-Image 2、Qwen-Image 2.0 の 3 つも同じプロンプトで手元に揃えてあります。この 3 つも日本語は問題なく描けていて、破綻率ではどれも「優」です。差は別のところに出ています。
たとえば GPT-Image 2 Thinking は、プロンプトに書いていない日本語の副題を自発的に足してきます。「実測!」だけでよかった吹き出しの横に「ドンッ」と勝手に書き足す。Nano Banana 2 はデザイン事務所のディレクターのように構図を整えてくる。Qwen-Image 2.0 は引き算の美学で、指示以上のものを置かない。読める文字が揃ったときに初めて、モデルの個性が「どんな文字をどう置くか」という層で比較できるようになった——この発見を、第 2 回と第 3 回でクローズド/オープンに分けて掘ります。
残したい問い
「崩れる日本語」という前提が外れたとき、次に見えてくるのは「何を描いてもらいたかったのか」という、より古い問いです。これまでは書けないから人間が書いていた。書けるようになったときに、モデルに渡すべき情報は何で、人間の側に残しておきたい判断は何か。
AI にダウンロードできる領域が広がることは、個人が組織として機能する規模を少しずつ押し上げてくれます。ただし、拡張された側が何を手元に残すのかを決めなければ、拡張そのものが目的化してしまう。この連載の終盤で向き合いたいのは、読める文字が手に入ったあとに、わたしの創作のどの層を「わたしが書くこと」として残したいのかという選択のほうです。
次回は、同じプロンプトセットで Nano Banana 2 と GPT-Image 2 Thinking を並べます。クローズドな 2 強が、文字が揃った世界で何を競っているのか——「書かれていないことまで書いてくる」という、新しい種類の逸脱が主題になる予定です。