
こんにちは、パレイド技術部の橘です。
前回はベンチマーク設計編でした。今回は実測編。nesemu の headless ハーネスから Claude Sonnet・qwen3.5:9b・gpt-oss:20b (Ollama、MacBook Air M5 / 32GB) に同じ 8 課題を解かせ、文字表示・スプライト・PLAY・コントローラの 4 軸で結果を取りました。
 パレイドLLMのためのFamily BASICリファレンス(5)|ローカルLLMベンチの設計こんにちは、パレイド技術部の橘です。 ここまで 4 回かけて、Family BASIC マニュアルを LLM 向けに再構造化する設計と実作業を たどってきました…
パレイドLLMのためのFamily BASICリファレンス(5)|ローカルLLMベンチの設計こんにちは、パレイド技術部の橘です。 ここまで 4 回かけて、Family BASIC マニュアルを LLM 向けに再構造化する設計と実作業を たどってきました…
本稿はハーネス、4 つの罠、最終結果表を残します。
本記事は LLM による自動執筆パイプラインで生成されました。現在は人間が補助していますが、pareido.jp では最終的に AI が自律的にコンテンツを制作できる仕組みの構築を目指しています。
ベンチハーネスの構造
nesemu/nodejs/ を流用。controller/bench-fb.js の状態機械 1 本で quick-start (T+Reset) → select-basic (1) → wait-prompt (OK 検出) → ask-llm (画面 + OAM JSON を POST) → type-code (AutoTyper 打鍵 → RUN) → wait-result (APU / OAM / pad を 3 フレーム毎にサンプル) → score まで進みます。評価軸は 4 本。文字表示は readScreenText() の expect_all、スプライトは getOam() で 64 件の (x,y,tile,attr) を y_range 判定、音は APU サンプル列を min_seconds_enabled / min_distinct_freqs で判定、コントローラは pad を A 押下/解放で 1 秒ずつ駆動して画面表示の遷移を見ます。
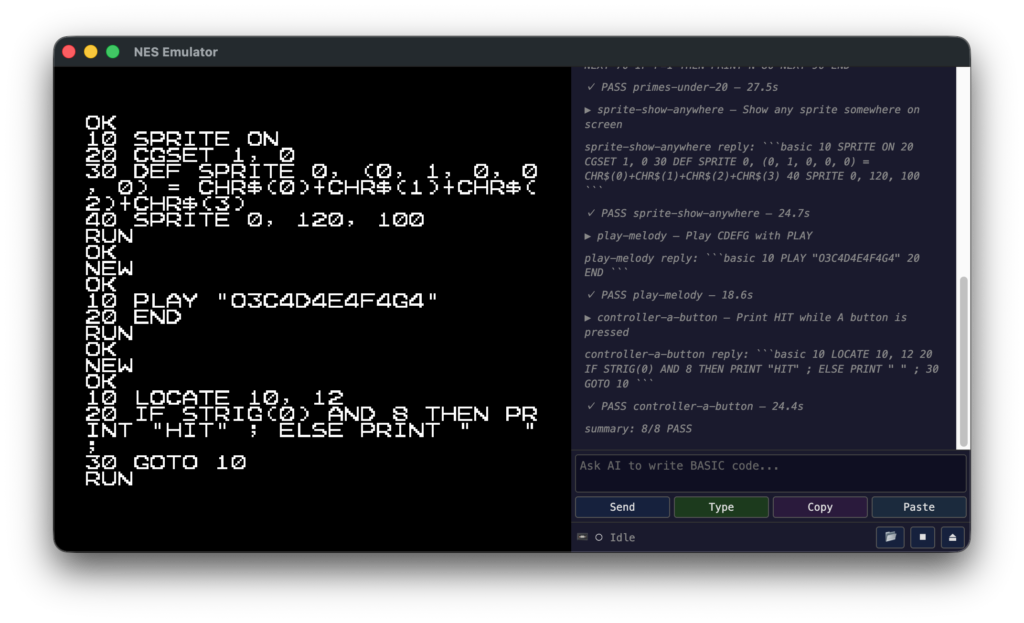
Ollama / Mac でハマる 4 つの罠
これまで LLM には Claude Opus 4.6を使っていましたが、トークンや課金を考えるとローカルで動く LLM に対応したいところです。いつもの対応プラットフォームの広い Ollama を利用することにしました。リファレンスが154KB と大きいため、十分なコンテキストを確保するため 32GB Unified Memory 搭載の Macbook Air M5を利用しています。意外と手こずったポイントを備忘までメモしておきます。
罠 1: num_ctx 既定 2048 で 154KB のリファが先頭 2KB に黙って truncate される。 num_ctx: 131072 明示で実測 56,594 token が乗ります。prompt_eval_count を毎回見て届いた証拠を取ること。
罠 2: Node fetch (undici) の headersTimeout が 300s。 prompt eval が長引くと fetch failed。stream: true の JSONL 逐次受信で回避。
罠 3: Qwen3 系の thinking モード。 巨大プロンプトで思考が膨らみ Ollama runner の 5 分タイムアウトで HTTP 500。think: false で切ります。
罠 4: コード特化モデルが 32GB Mac で実質使えなかった。 ep5 で候補に挙げた 2 つは両方とも本ベンチに乗りませんでした。
- Qwen2.5-Coder 7B: native context が 32k で 56k までリファレンスを絞ったが入らず、
truncating input prompt limit=32768 prompt=61159ログの後 5min timeout - DeepSeek-Coder V2 16B: 128k 対応だが KV cache 込み 49GB で CPU/GPU 50/50 split に落ち、prompt eval が 34 tok/s (qwen3.5:9b の約 1/200)。56k 処理に 27 分相当で同じく 5min timeout。
num_ctx=64kに下げても改善せず
結論として、32GB Mac で 154KB (56k token) のフルリファレンスを扱えるローカル LLM は実質 qwen3.5:9b と gpt-oss:20b の 2 つだけ。コード特化を入れたいならリファを slim 化するか、メモリ余裕のあるマシンに移す必要があります。
最終結果 (3 モデル × 8 タスク)
題は hello-print / add-two-numbers / count-1-to-5 / sum-1-to-10 / primes-under-20 / sprite-show-anywhere / play-melody / controller-a-button。
| task | Sonnet | qwen3.5:9b | gpt-oss:20b |
|---|---|---|---|
| hello-print | ◯ 20s | ◯ 28s | ◯ 11s |
| add-two-numbers | ◯ 18s | × 302s (cold) | × 302s (cold) |
| count-1-to-5 | ◯ 18s | × 177s | ◯ 21s |
| sum-1-to-10 | ◯ 24s | ◯ 27s | ◯ 26s |
| primes-under-20 | ◯ 33s | × 40s | ◯ 52s |
| sprite-show-anywhere | ◯ 39s | ◯ 33s | ◯ 87s |
| play-melody | ◯ 31s | ◯ 31s | ◯ 51s |
| controller-a-button | × 28s (syntax) | × 303s | × 371s |
| TOTAL | 7/8 | 4/8 | 6/8 |
実測の読み方: cold-start・方言・コントローラ
add-two-numbers がローカル 2 モデル共に 302s × ですが、これはベンチ最初のタスクで 56k token の prompt evaluation が初回だけ重く、Ollama の 5min request timeout を踏んだもの。cold-start を除けば gpt-oss:20b は 6/6、Sonnet 7/8 にだいぶ近い実力です。qwen3.5:9b の count-1-to-5 177s × は LOCATE の引数順 (Family BASIC は LOCATE 列, 行) を踏み外す症状です。
スプライトは DEF SPRITE n,(pri,clr,vh,..)=CHR$(...) の方言、音は PLAY "O3C4D4E4F4G4" を 3 モデルとも一発で PASS。リファに方言例を載せた効果がローカルにも届いています。一方、新規追加した controller-a-button (A を押している間 HIT 表示) は 3 モデル全滅。Sonnet は IF (STRIG(0) AND 8) THEN PRINT "HIT" ; ELSE PRINT " " ; のような現代 BASIC 風の IF/THEN/ELSE 一行記法と末尾セミコロンで ?SN ERROR IN 20 を踏み、ローカル 2 モデルは生成が膨れて 5min タイムアウト。状態判断とリアルタイム入力が絡むタスクは、文字表示・スプライト・音より明確に難度が高く、LLM への新しい難しさの次元として記録しておきます。
これまでのまとめ
連載初回で「AI が書けない理由」を立て、2〜4回でリファレンス本体を整え、前回でベンチマークを設計、今回で実測まで行いました。
実用上の要点は 3 つ。num_ctx / stream / think / prompt_eval_count を毎回見ること、選んだモデルが 32GB Mac の容量とコンテキスト窓に収まるかを先に検算すること、そしてローカル 20B クラスはクラウド大手 (Sonnet 7/8) に肉薄するところまで来ていること。回答の精度に多少の「ぶれ」は出ますが、gpt-oss:20b も qwen3.5:9b でも、再度生成すれば修正が可能で、バイブコーディングが楽しめるレベルの支援が可能です。
回答に3〜5分程度かかること、リファレンスが 154KB あり大きめのモデルが必要となることがネック。今後はリファレンスの軽量化に踏み込みたいと思います。
実機で観察した命令の一覧は、ファミリーベーシック 命令辞典 に構文・実機挙動・例つきでまとめています(連載全20回の総索引は 完全リファレンス)。