

こんにちは、パレイド思想部です。
新連載「バーチャルAI実験:人間が答えるチャットボットの構築」の第 1 回をお届けします。
人とAIが融合した集合知の実験を始めます。LINE で届いた相談に、無数の登録ユーザーの誰かが答える。答えられる人が、答えられるときに。——人間からは一つのAIに対峙しているように見える。「バーチャル人力AI」が完成するはず。
AIチャットボットが当たり前になった時代に、あえて人間を主役に据えたらどうなるか。回答の質は? スピードは? そもそも人は答えてくれるのか? この連載では、その実験システムを構築していきます。
第 1 回となる今回は、基盤構築に焦点を当てます。FastAPI による非同期サーバーと、ngrok によるローカル環境の公開までを一気に整えます。
本記事はローカル LLM による自動執筆パイプラインで生成されました。現段階ではクラウド AI(Claude 等)の補助や人間の編集が介在していますが、pareido.jp では最終的に AI が自律的にコンテンツを制作できる仕組みの構築を目指しています。
1. プロジェクトの全体像と設計意図
まず、このシステムがどう動くかを押さえましょう。
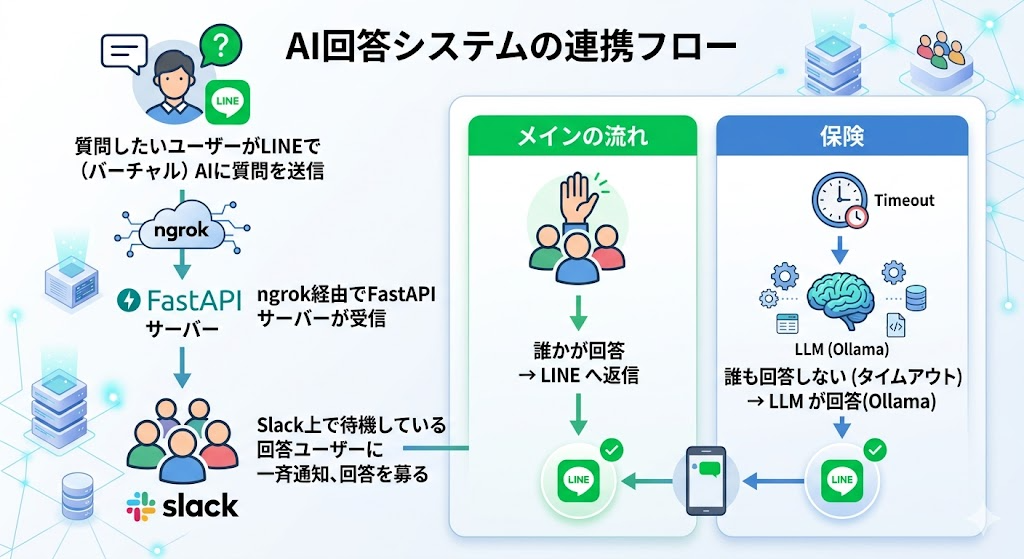
ポイントは人間が主役であることです。LLM は「誰も答えられなかったとき」のセーフティネット。一般的なチャットボットとは発想が逆で、「人間の知恵をまず集め、集まらなければ AI に頼る」というアーキテクチャです。
この仕組みを支える技術スタックは以下の 3 つです。
- FastAPI: Python の非同期処理に最適化された Web フレームワーク。Slack への通知と LLM へのリクエストを並行して扱えます。
- Ollama: ローカル環境で動く軽量 LLM。コスト抑制とプライバシーを両立する、保険としての回答生成エンジンです。
- ngrok: ローカル PC を一時的にインターネット公開するトンネリングツール。LINE や Slack の Webhook を受信するために使います。
2. 環境変数の管理:.envファイルの作成
早速チャットUIを構築といきたいところですが、先にアクセス情報の管理について整理しておきます。 LINE のアクセストークンや ngrok の認証キーなど多数のセンシティブな情報を使いますので、ハードコードは避けます。 うっかりクラウドサービスのAIに見せないようにするのも重要です。
良し悪しは諸説ありますが、よく使われる .env ファイルを作成し、必要な環境変数を定義する方式とします。
.envファイルの構成例
# LINE 公式アカウントの認証情報
export LINE_CHANNEL_SECRET="your_line_channel_secret_here"
export LINE_CHANNEL_ACCESS_TOKEN="your_line_channel_access_token_here"
# Slack の認証情報(回答者への通知に使用)
export SLACK_BOT_TOKEN="your_slack_bot_token_here"
export SLACK_SIGNING_SECRET="your_slack_signing_secret_here"
# ngrok の認証トークン(固定ドメイン取得用)
export NGROK_AUTHTOKEN="your_ngrok_auth_token_here"
# 本番環境での Webhook URL(ngrok 起動後に自動取得されるが、手動設定も可能)
export WEBHOOK_URL="your_ngrok_webhook_url_here"ポイント: export 記述は Linux/Mac 用です。Windows の PowerShell 環境では後述の start.ps1 で読み込む形式になりますが、.env ファイル自体は OS に関係なく同じ形式で管理するのが一般的です。
.env.exampleの作成と.gitignore
チーム開発や公開リポジトリにおいて、.env ファイルを Git にコミットして漏洩させる事故は頻発します。これを防ぐため、以下のように設定します。
.env.exampleの作成: 実際の値を空にしたテンプレートファイルをリポジトリに置きます。.gitignoreの設定:.envファイルを Git の管理対象から除外します。
.gitignoreを作成します。
# 環境変数(絶対にコミットしない)
.env
# Python 関連
__pycache__/
*.py[cod]
.venv/
*.egg-info/
# DB ファイル
app.db
# ngrok ログ
/tmp/ngrok.log
# OS 関連
.DS_Store
Thumbs.dbAIを利用している方にも、.gitignore をポリシーで避ける設定が使える場合もありおすすめです。
3. 基盤となるapp.pyの構造設計
次に、プロジェクトの心臓部である app.py を設計します。
LINE からの質問を受け取り、Slack への通知と Ollama への保険リクエストを並行して扱えるスケルトンを作ります。
FastAPI アプリの骨組み
import os
import asyncio
from fastapi import FastAPI, Request, HTTPException
from dotenv import load_dotenv
# 環境変数の読み込み
load_dotenv()
app = FastAPI(title="Virtual AI - Human-Powered Chat")
# 環境変数の取得(存在しない場合はエラーを吐くようにする)
LINE_CHANNEL_SECRET = os.getenv("LINE_CHANNEL_SECRET")
LINE_CHANNEL_ACCESS_TOKEN = os.getenv("LINE_CHANNEL_ACCESS_TOKEN")
SLACK_BOT_TOKEN = os.getenv("SLACK_BOT_TOKEN")
# LINE Webhook 受信エンドポイント
@app.post("/webhook/line")
async def line_webhook(request: Request):
body = await request.json()
# 質問を受け取ったら:
# 1. Slack の回答者チャンネルへ一斉通知
# 2. タイムアウト後に誰も答えなければ Ollama に回答を依頼
# 第 2 回で詳細を実装します
return {"status": "ok", "message": "Webhook received"}
# ヘルスチェック用エンドポイント
@app.get("/")
async def root():
return {"status": "running", "project": "Virtual AI"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)設計のポイント:非同期処理の準備
このコードの肝は async def で定義された関数です。
LINE から質問が届いた瞬間に Slack へ通知を飛ばし、人間の回答を待ちつつ、裏で Ollama にも保険のリクエストを準備しておく並行処理は、FastAPI + asyncio で実装します。
4. ローカル環境から Webhook を受信する:ngrokの設定
LINE や Slack の Webhook 設定には、「公衆インターネットからアクセス可能な HTTPS エンドポイント」が必須です。
自宅の PC は外部から直接アクセスできないため、ngrok で一時的な公開 URL を作成します。
ngrokのインストールと設定
- ngrok の公式サイトからツールをダウンロードし、インストールします。
- 自身の ngrok アカウントで発行された
Auth Tokenを.envのNGROK_AUTHTOKENに記述します。
起動スクリプトstart.sh(Mac/Linux 用)
#!/bin/bash
# 環境変数の読み込み
source .env
# 既存のプロセスを停止(ngrok と uvicorn)
pkill -f ngrok
pkill -f uvicorn
echo "🚀 バーチャルAI サーバーを起動中..."
# 1. ngrok を起動してトンネルを確保
ngrok http 8000 &
NGROK_PID=$!
# 2. ngrok の URL 取得を待つ(最大 10 秒)
echo "⏳ ngrok の URL 取得を待っています..."
sleep 5
echo "✅ ngrok 起動完了!"
echo "🔗 Webhook URL: http://localhost:4040/status (ngrok のステータスページ)"
echo "⚠️ 実際の Webhook URL は ngrok のターミナル出力または https://dashboard.ngrok.com から確認してください"
# 3. FastAPI アプリを起動
uvicorn app:app --reload
# 4. スクリプト終了時に ngrok とアプリを停止
trap "kill $NGROK_PID; pkill -f uvicorn; echo '🛑 システムを停止しました。'" EXIT固定ドメインの取得(推奨)
無料版の ngrok は URL が毎回変わります。LINE の Webhook 設定を毎回変更するのは手間なので、ngrok の固定ドメイン機能を利用し、.env に NGROK_DOMAIN として設定しておくと開発がスムーズです。
5. 動作確認とデバッグ
準備が整いました。以下の手順で起動しましょう。
- 仮想環境の作成と依存ライブラリのインストール
bash python -m venv .venv source .venv/bin/activate # Windows なら .venv\Scripts\activate pip install -r requirements.txt .envファイルに実際のトークンを記述する。- 起動スクリプトを実行
bash chmod +x start.sh ./start.sh
ブラウザで http://localhost:8000/ にアクセスし、{"status": "running", "project": "Virtual AI"} が返ってくれば、基盤構築は完了です。
まとめ
第 1 回では、バーチャルAI チャットシステムの土台を固めました。
- FastAPI による非同期 Web サーバーの設計
.envによる機密情報の安全な管理ngrokによるローカル環境の公開
次回は、この土台の上に「Slack への一斉通知」「人間の回答待ち」「LLM フォールバック」のコアロジックを実装します。人間が答えてくれるのか、それとも LLM の出番になるのか——その仕組みを一緒に作りましょう。
次回予告
第 2 回:コアロジック——人間優先の応答システムと LLM フォールバック
* Slack への一斉通知と回答待ちの実装
* タイムアウト制御と Ollama フォールバック
* asyncio を使った並行処理パターン

