

こんにちは、パレイド思想部です。
前回は LLM による記事自動生成の仕組みを紹介しました。「生成できた」という達成感とともに、ふと浮かぶ疑問があります。「この文章、本当にそのまま出して大丈夫か?」

事実誤認・構成崩れ・前の記事との矛盾。自分で書いたなら読み返せばわかる。でも LLM が吐いた文章を毎回隅々まで目視チェックするのでは、自動化の意味が半減します。
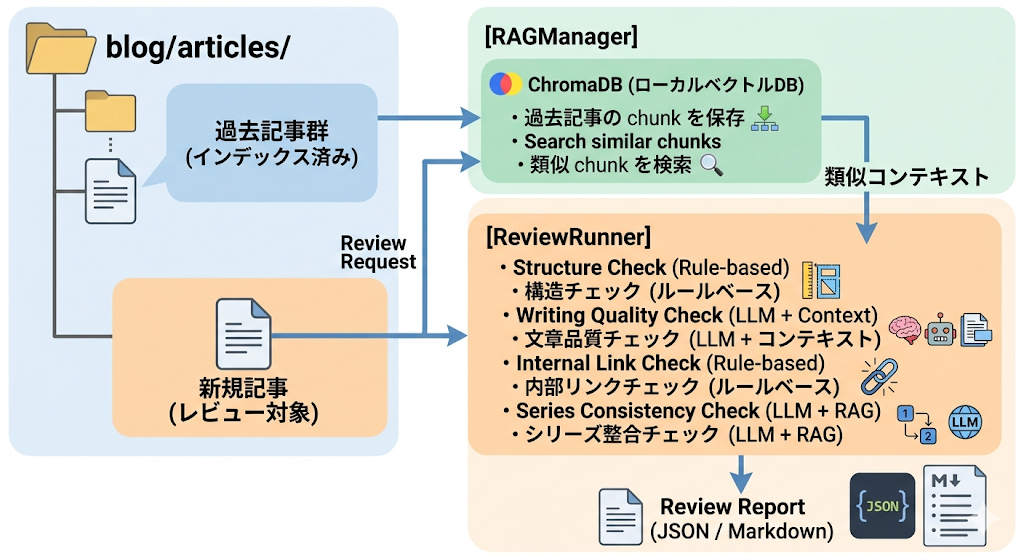
ai-editor ではこの問題を ChromaDB ベースの RAG レビュー で解決しています。今回はその設計と実装を、実際のチェックレポート例を交えながら紹介します。
なぜ「レビューの自動化」が必要か
LLM 生成テキストの品質問題は大きく 4 種類に分類できます。
| カテゴリ | 具体例 |
|---|---|
| 構造 | 見出し階層が崩れている、frontmatter が欠損 |
| 文章 | 断言すべき箇所が曖昧、冗長な言い回し |
| 内部リンク | 前回記事への参照が抜けている、URL が壊れている |
| シリーズ整合 | 前の記事との整合性。例えば用語のブレや、 「次回は〇〇を解説」と書いたのに触れていない |
このうち構造と内部リンクはルールベースで機械的に検出できます。 問題は文章品質とシリーズ整合です。後者は「過去記事を読んだ上でないと判断できない」という性質を持つため、RAG が力を発揮します。
RAG レビューの全体像
RAG を行うには、あらかじめ WordPress API を利用してダウンロードした記事を Chroma DB でベクトル化しておく必要があります。(2026年3月追記 図を差し替え)
ChromaDB を選んだ理由
ベクトル DB の選択肢はいくつかあります。
| ライブラリ | 特徴 | 不採用理由 |
|---|---|---|
| Pinecone | クラウド管理、スケーラブル | 外部依存・課金発生、個人ブログには過剰 |
| FAISS | 高速・軽量 | メタデータ検索が弱い、永続化が手動 |
| Weaviate | フル機能 | Docker 必須、セットアップコストが高い |
| ChromaDB | ローカル動作・永続化・メタデータ対応 | ← 採用 |
ChromaDB はローカルのディレクトリに永続化でき、article_id や series などのメタデータでフィルタリングできます。個人ブログで100~200程度の記事数という規模では、これが最も費用対効果が高い選択でしょう。
実装:RAGManager
# tools/publish/review/rag_manager.py(抜粋)
import chromadb
from chromadb.utils import embedding_functions
class RAGManager:
def __init__(self, db_path: str, embed_model: str = "nomic-embed-text"):
self.client = chromadb.PersistentClient(path=db_path)
# Ollama の埋め込みモデルを使用(ローカル・無料)
self.ef = embedding_functions.OllamaEmbeddingFunction(
url="http://localhost:11434/api/embeddings",
model_name=embed_model,
)
self.collection = self.client.get_or_create_collection(
name="articles",
embedding_function=self.ef,
)
def index_article(self, article_id: str, chunks: list[str], meta: dict):
"""記事を chunk 単位でインデックスに追加"""
ids = [f"{article_id}_{i}" for i in range(len(chunks))]
metadatas = [{**meta, "chunk_index": i} for i in range(len(chunks))]
self.collection.upsert(documents=chunks, ids=ids, metadatas=metadatas)
def query(self, text: str, n_results: int = 5, where: dict | None = None) -> list[str]:
"""類似 chunk を検索して返す"""
results = self.collection.query(
query_texts=[text],
n_results=n_results,
where=where,
)
return results["documents"][0]埋め込みモデルには Ollama の nomic-embed-text を使っています。APIキーを使った OpenAI の モデルを使いたいところですが、記事のインデックス更新は頻繁に発生するため、API コストが積み上がります。ローカル埋め込みなら再インデックスを何度も気兼ねなく走らせられます。
実装:シリーズ整合チェック
最も価値のあるチェックがこれです。「前回の予告と今回の内容が一致しているか」を LLM に判断させます。
# tools/publish/review/review_runner.py(抜粋)
def check_series_consistency(self, article: Article) -> CheckResult:
if not article.meta.get("series"):
return CheckResult(passed=True, message="連載外記事はスキップ")
# 同連載の直前記事を RAG で取得
prev_chunks = self.rag.query(
text=article.body[:500],
n_results=8,
where={"series": article.meta["series"]},
)
prompt = f"""
以下は連載記事のレビュータスクです。
## 参照コンテキスト(同連載の過去記事から抜粋)
{chr(10).join(prev_chunks)}
## 今回の記事
{article.body[:2000]}
## 確認事項
1. 過去記事が「次回は〇〇を紹介する」と予告していた場合、今回の記事はそれを満たしているか?
2. 前回記事で定義された用語・概念と矛盾していないか?
3. シリーズの論旨の流れとして自然か?
JSON で回答してください: {{"passed": bool, "issues": [str], "suggestions": [str]}}
"""
raw = self.llm.complete(prompt)
return CheckResult.from_json(raw)設計のポイント: LLM に「全文読め」とは言いません。RAG で取得した関連 chunk だけを渡すことで、コンテキスト長を抑えつつ必要な情報を届けます。これにより 32k トークンのモデルでも数十記事規模の連載を扱えます。
実際のレビューレポート例
# レビューレポート: 2026-03-16_ai-auto-edit-pipeline.md
## 構造チェック ✅ PASS
- frontmatter: 必須フィールドすべて存在
- 見出し階層: 正常(h2 → h3 の順序)
## 内部リンクチェック ⚠️ WARN
- 参照先 `/ai-editor-series-03/` が記事一覧に存在しません
→ スラッグの表記ゆれの可能性(`ai-editor-3` と混在)
## 文章品質チェック ⚠️ WARN
- 「〜と思われます」が 3 箇所。技術記事では断定推奨
- 同一段落内で「自動化」が 4 回繰り返し。言い換え検討を
## シリーズ整合チェック ✅ PASS
- 前回予告「次回はパイプラインの全体像を解説」→ 今回記事で充足
- 用語「gnosis」の定義は前回記事と一致
## 総合判定: WARN(自動公開保留 / 人間確認推奨)PASS / WARN / FAIL の 3 段階で判定し、FAIL は自動公開をブロック、WARN はフラグを立てて人間に委ねます。「全部 PASS にならないと公開できない」では厳格すぎてワークフローが詰まるため、この中間段階が重要です。
チェック設計のトレードオフ
「全項目を LLM に任せればよいのでは?」 という疑問は自然です。しかし構造チェックやリンク検証をルールベースに留めた理由があります。
LLM は「frontmatter の post_id フィールドが存在するか」を確認するのに、数百トークンを消費します。正規表現なら 0.1ms です。確実に正誤が判断できるものはコードで、文脈依存の判断が必要なものだけ LLM に委ねる。この分担がコストと精度の両立につながります。
まとめ
- RAG レビューは 4 種類のチェック(構造・文章・リンク・シリーズ整合)を自動化する
- ChromaDB + Ollama 埋め込みでローカル完結・コストゼロのベクトル検索を実現
- ルールベースと LLM の役割分担がスループットと精度を両立させる
PASS / WARN / FAILの判定でワークフローの詰まりを防ぐ
「AIの文章を信頼できるか」は、信頼できるまでチェックする仕組みを作ることで答えが出ます。完璧な自動化ではなく、人間の最終判断を効率よく引き出す補助装置として設計する。それがこのレビュー層のコンセプトです。
次回予告: 第5回では、サムネイルの自動生成に進みます。

