

こんにちは、パレイド技術部です。
連載「バーチャルAI実験:人間が答えるチャットボットの構築」のまとめ記事です。本編 3 回と補足 3 回、計 6 本の記事で構築してきたシステムを振り返ります。
本記事はローカル LLM による自動執筆パイプラインで生成されました。現段階ではクラウド AI(Claude 等)の補助や人間の編集が介在していますが、pareido.jp では最終的に AI が自律的にコンテンツを制作できる仕組みの構築を目指しています。
連載の全体像
この連載では「LINE で届いた質問に、まず人間が答える。誰も答えられなければ LLM が保険として回答する」というバーチャルAI を構築しました。
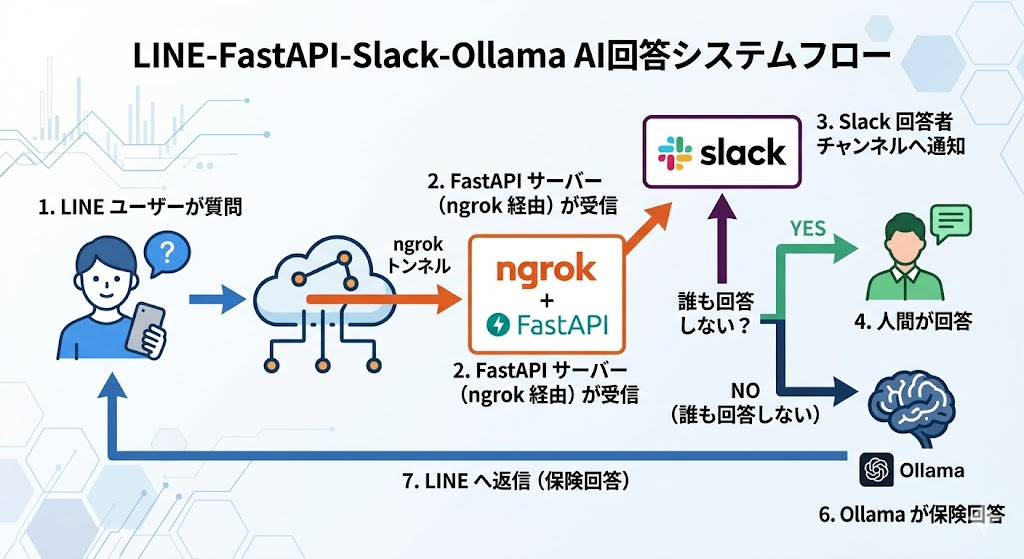
各記事の内容は以下の通りです。
技術スタックと設計判断
採用した技術スタックは 4 つです。
- FastAPI:
async/awaitで Slack 通知と LLM リクエストを並行処理 - Slack SDK: 回答者チャンネルへの通知と、スレッド返信イベントの受信
- Ollama: ローカルで動く LLM。コスト抑制とプライバシーを両立する保険回答エンジン
- ngrok: ローカル PC を HTTPS で公開。固定ドメイン機能で Webhook URL の再設定を不要に
設計で最も重要だったのは「人間の回答を待ちつつ、裏で LLM にも回答を準備させる」並行処理パターンです。asyncio.create_task で両方を同時に走らせ、人間が答えたら LLM タスクをキャンセルする。逆にタイムアウトしたら LLM の結果をそのまま使う。この仕組みにより、フォールバック時の待ち時間を最小化しました。
実験で見えたこと
人間が「AIの代わり」を務める意義
答えられる人がいて、答える余裕があるとき、人間の回答は LLM を超えます。文脈を踏まえた丁寧な回答になりやすく、ハルシネーションのリスクもありません。
しかし、24 時間安定して回答を返すのは人間には難しい。タイムアウトが頻発する時間帯では LLM ばかりが答えることになり、「普通のチャットボット」と変わらなくなります。
また、匿名性も手伝って、いたずらや悪意ある回答が増えたり、意図しない誤解等も当然混ざってきます。この点を予防する技術的な補助や、相互レビュー的な仕組みの構築が必要でしょう。
タイムアウト値のジレンマ
短くすると LLM の出番が増え、長くするとユーザーを待たせます。また、ユーザーによってはじっくり考えて回答したいという方も多いでしょう。60 秒は一つの目安ですが、最適値は運用データを見ながら探る必要があります。
実際、初期は回答そのものを 60 秒以内に入力するルールでしたが、あまりに厳しく回答がむずかしかたたため、はじめに「挙手」ボタンを押して回答の権利を獲得すると、さらに60秒プラスで回答の猶予が与えられる、といったルールで緩和しました。
また、さらに回答時間に猶予を持たせるため、ユーザーが回答中であることを表示したり、間を LLM の雑談(「フィラー」と呼ぶようです)で繋ぐ等の工夫をすることで、徐々に現実的なプロセスを詰めていきました。
バイブコーディングの注意点
FastAPI + asyncio + Slack API + Ollama という組み合わせで、人間優先・LLM フォールバックの仕組みは意外とすっきり実装できました。複雑なのはコードではなく、LINE・Slack・ngrok それぞれの管理画面での設定手順の方です。補足記事 3 本はまさにその部分を補うために書きました。
本連載も、AI支援によるバイブコーディングで実装を行いました。各サービスが連携して動くまでは早いのですが、これ以上の機能拡張を入れようとすると、どこかで問題が起こるモグラ叩きの状態となります。テスト、git管理など、一定のソフトウェア開発の知識があるとスムーズでしょう。
発展の可能性
このシステムを土台にして、さらに広げられる方向性があります。
- 回答品質のフィードバック: LINE ユーザーが「役に立った / 立たなかった」を返せる仕組みを追加し、人間と LLM の回答品質を定量比較する
- 回答履歴の RAG 化: 過去の人間の回答を蓄積し、LLM のフォールバック回答の精度を向上させる。またWebで人気の会話を公開する
- 回答者向けの報酬: ポイント制や実績解放のシステムなど、回答してくれるユーザーへの報酬体系と具体的な実装を整備する
- 本番デプロイ: ngrok を VPS に置き換え、24 時間稼働させる
- 大型モデルでのLLM回答の質の向上 : 今回は実験目的のため、Ollama と gemma3:4b という軽い構成を取りました。雑談にはこれで十分ですが、より高機能なAPIキーを利用するクラウドAIを組み合わせれば、双方の発言のチェックなどの発展系も考えられます
また、本アプリは N 対 1 での匿名性の会話ですが、1 対 1 する、実名やハンドル名を公開するといった「昇格」のシステムがあっても面白いでしょう。いわゆる「知恵袋」的な掲示板や、ある種の人材マッチングサービスとして間口を広げられる可能性もあります。
まとめ
「AI にすべてを任せる」のではなく、「人間の知恵をまず集め、集まらなければ AI に頼る」。この逆転の発想でチャットボットを作ってみた結果、人間が主役になれる場面は確かにあることがわかりました。一方で、安定稼働という点では AI の信頼性が際立つことも事実です。
どちらか一方ではなく、両者を組み合わせるアーキテクチャに可能性がある——それがこの実験で得られた最大の知見です。
連載にお付き合いいただき、ありがとうございました。

